ISA中的指令格式设计与寻址模式
此篇笔记有关指令集体系结构(ISA, Instruction Set Architecture),重点关注指令格式及其含义,以及几种主要的寻址模式
ISA中的指令格式设计与寻址模式
关于处理器如何执行指令乃至程序,请移步我的另一篇相关笔记:处理器执行程序与指令的流程详解
一、关于指令
1.1 指令的类型
- 内存与处理器寄存器间的数据传输
- 算数运算、逻辑运算
- 指令执行的顺序控制
- 沟通外部的数据输入输出传输
1.2 指令的RTN表示
- 寄存器传输表示(RTN, Register Transfer Notation)被用于描述硬件层级的数据传输与操作
- 处理器寄存器地址:$R0,R1,…,R5$
- I/O寄存器地址:DATAIN,OUTSTATUS
- 内存地址:LOC,PLACE,A,VAR2
- 使用$[…]$表示地址$…$上的数据内容,用$\leftarrow$表示数据传输到某个目的地,箭头右侧始终表示值,左侧始终表示一个地址
- $R2\leftarrow[LOC]$:数据从内存中的$LOC$传输到处理器的$R2$上
- $R4\leftarrow[R2]+[R3]$:将处理器的$R2$与$R3$上的值相加后赋予$R4$寄存器
1.3 指令的汇编表示
- 汇编语言表示(Assembly-Language Notation)是专门用于编写更复杂的机器指令程序的,而单纯的RTN表示无法满足这样的需求,上面的RTN表示的两个例子用汇编语言表示如下
- $R2\leftarrow[LOC]$:Load R2, LOC
- $R4\leftarrow[R2]+[R3]$:Add R4, R2, R3
- 上面使用简单的英文单词表示指令中执行的操作,而商业处理器中通常使用Mnemonics,其使用简写LD、ADD等简写来表示指令,在不同的处理器中这些简写有所差异
1.4 RISC与CISC的区别
- 精简指令集计算机(RISC, Reduced Instruction Set Computers)
- 单Word指令,指令集小(选取使用频率较高或很有用但不复杂的简单指令,让复杂指令的功能由这些简单指令组合以实现)
- 指令长度固定,寻址方式种类少,单个指令均能在一个时钟周期内完成
- 需要先从内存中加载操作数到处理器寄存器上(Load),才能对寄存器上的值进行读写操作,时候可能还需要将其返回内存中保存(Store)
- 每个程序的指令数量更对
- 硬件结构相对简单,较容易设计出高速处理器
- 复杂指令集计算机(CISC, Complex Instruction Set Computers)
- 多Word指令,指令集复杂庞大(200~300条)
- 指令长度可变,寻址方式种类多,单个指令需要多个时钟周期来执行
- 允许直接使用内存中的操作数,而无需先加载到寄存器中(Memory-To-Memory)
- 每个程序的指令数量更少
- 硬件结构更复杂,较难(但不是不可能)设计高速处理器
1.5 RISC指令执行示例
1.5.1 普通指令
- RISC中的操作数必须先被加载到处理器寄存器上才能被继续处理(可见在游戏图灵完备中实现的处理器应当是RISC架构的)
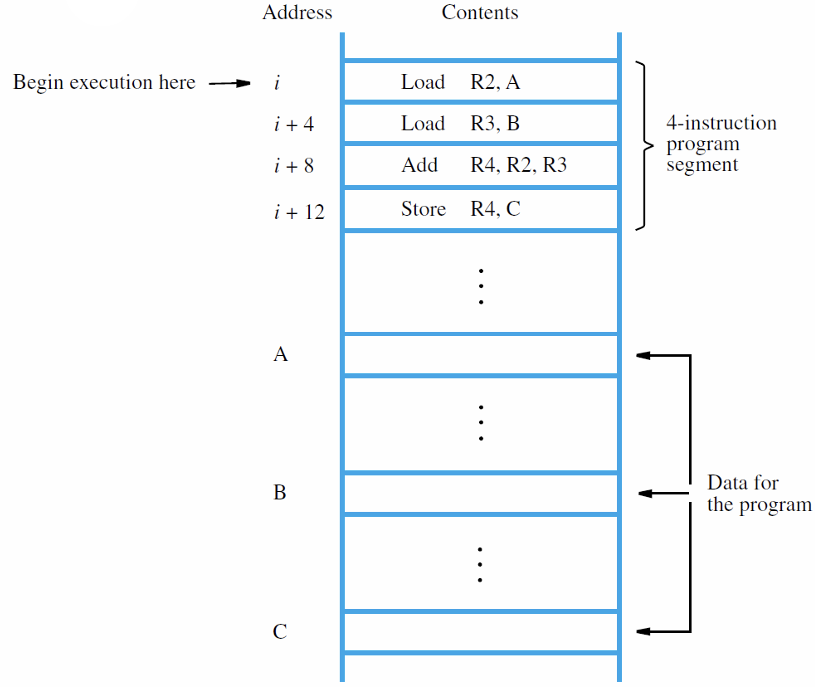
- 比如执行RTN的$C\leftarrow[A]+[B]$指令就需要以下四个步骤,如下图所示
- Load R2, A
- Load R3, B
- Add R4, R2, R3
- Store R4, C
1.5.2 分支指令
- 若想打印一系列的数据,这需要我们循环运行一组判断性的指令,若不满足结束的边界条件就会跳转回这组指令的起点,类似C++的
goto关键字的作用,这种指令称为分支(Branch)指令 - 程序计数器(PC, Programme Counter)的值对应程序指令序列中的特定指令,正常情况下其会从程序起点开始自增,按顺序指向对应需要被执行的指令
- 分支指令是一种重要的控制流指令,用于选择性地改变程序计数器来执行不同的指令序列,从而实现跳转和循环等指令执行逻辑
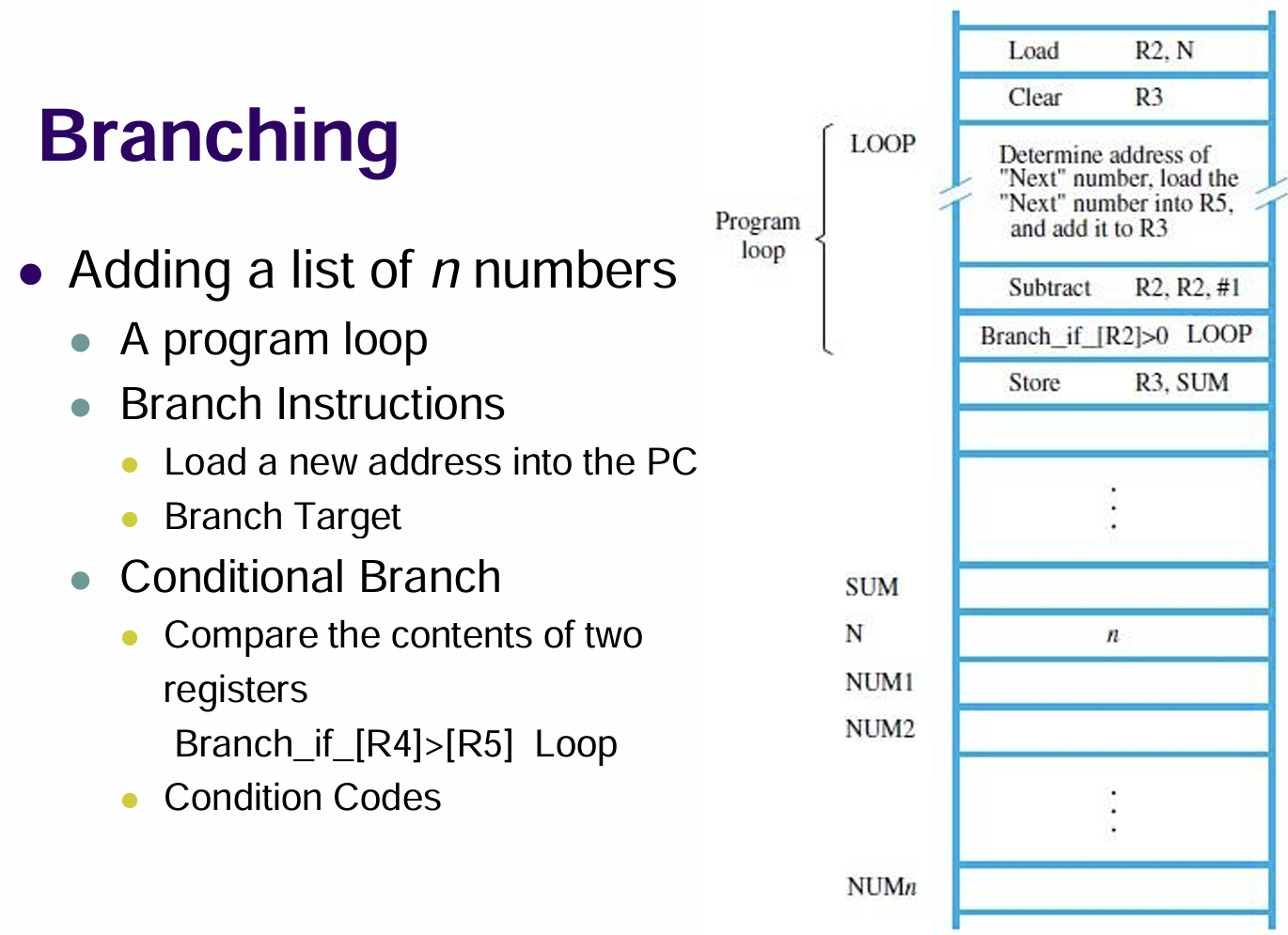
- 在游戏图灵完备中也有一关需要我们编写类似的一个程序,让我用自己搭建的RISC处理器实现一个输入$n$然后输出$6n$的乘法,相关汇编代码详见相关文章末尾
二、指令格式
2.1 指令的组成元素
- 指令由二进制序列组成,该序列的不同字段可被解码($n$bit的编码可被解码为$2^n$种含义)为不同的指代含义,映射不同的操作方法(Opcode)或操作数(Operand)地址
- Operation Code(Opcode)
- 操作码,解码后决定该指令对操作数执行什么操作,如ADD
- Result Operand Reference
- 目的操作数,即存放操作的结果的容器地址(主虚存、处理器寄存器、IO设备)
- 在指令二进制序列中,该字段紧贴操作码字段
- Source Operand Reference
- 被执行操作的操作数(可能多个)所在的地址
- Operation Code(Opcode)
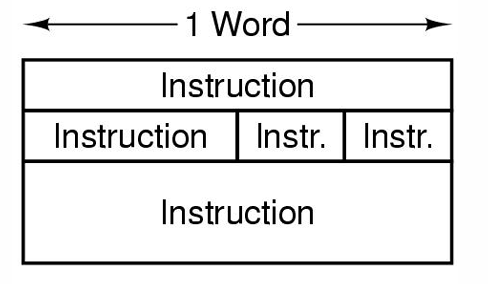
- 如下图,其中Opcode Field用于存储操作码,Address Field用于存储(目的、源)操作数的地址,Address Field中可以指代的操作数的数量依据设计需要会有所不同

- 无操作数(无地址)的指令,只有一个操作码
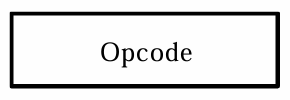
- 单操作数(单地址)指令,常用于对该操作数自增自减,比如设计一个让程序中的指令序列按时间顺序执行的计时器

- 多操作数(多地址)指令,其中紧贴操作码的是目的操作数,其余是一个或多个被运算的操作数


2.2 定长指令与不定长指令
- 所有定长指令长度相同(由于对于不同的操作码指令,其所用到的操作数数量不同,Address Field的长度也不同,固定的指令长度会导致所需操作数少的操作码指令的Address Field会产生未定义的指令)
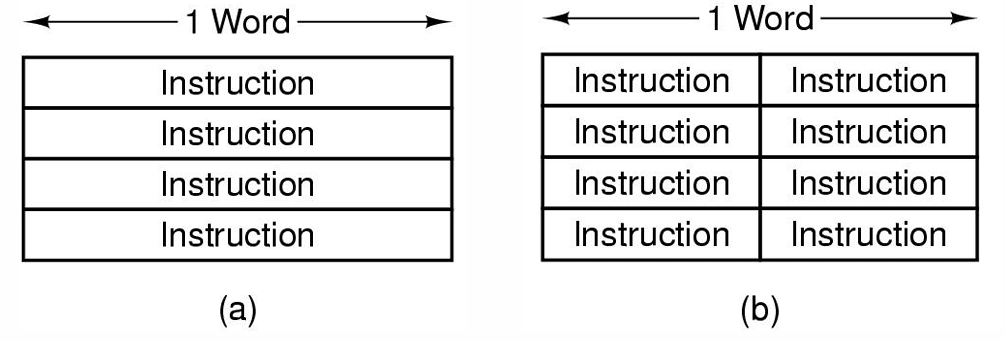
- 可变长度指令
2.3 定长操作码与扩展操作码
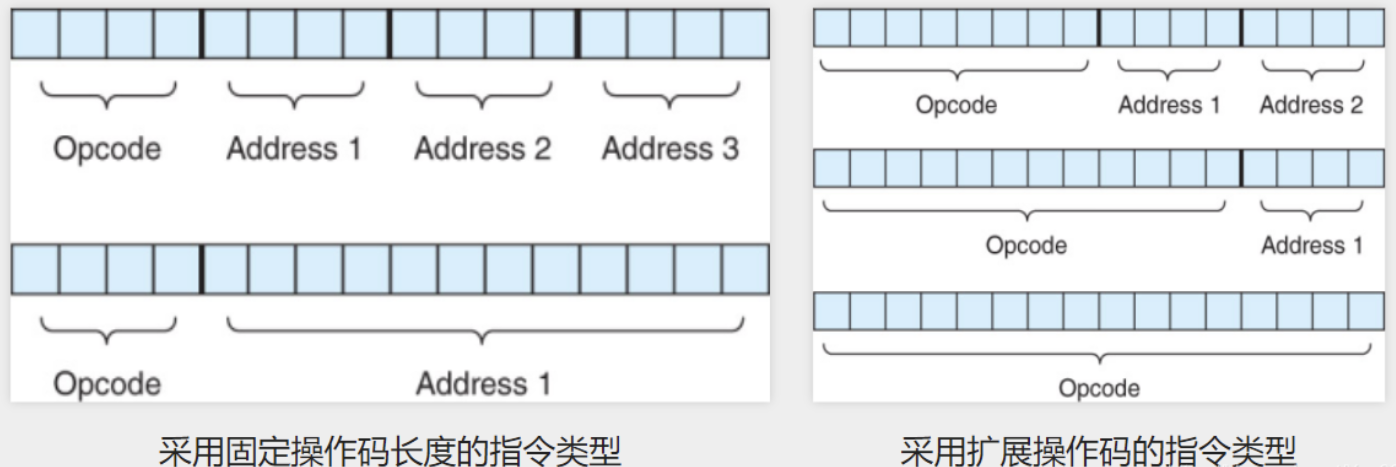
- 定长操作码,通常整体指令长度被设计为可变的,如$k$位的操作数可以最多映射$2^k$种不同的操作
- 扩展操作码(Expanding Opcode)的长度可变,其作用是为了在定长的指令中,通过变长的操作码来表示更多的操作类型(指令类型)
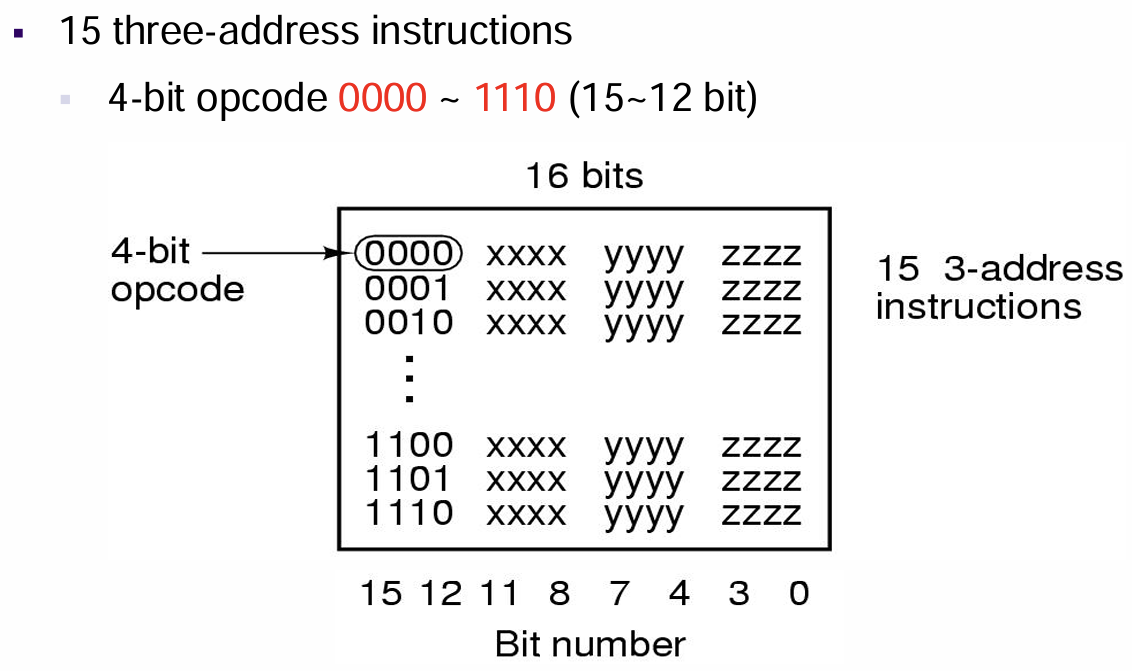
- 假设某处理器体系结构中有$16=2^4$个寄存器(由此推出需要$4$位编码作为寄存器地址),采用$16$位长度的指令,这样定长的指令中如果采用扩展操作码,则可以有四种形式:$4$位、$8$位、$12$位和$16$
- $15$条三地址指令:对于$4$位扩展操作码,其拥有三个可用的地址位来对应三个操作数,我们将其译码后选择前$15$种作为不同的三操作数的指令,而余下的$1111 …$则当作非三操作数指令的标识,不然的话无法区分是不是$4$位的扩展操作码(即无法确定哪些是地址、哪些是操作码)
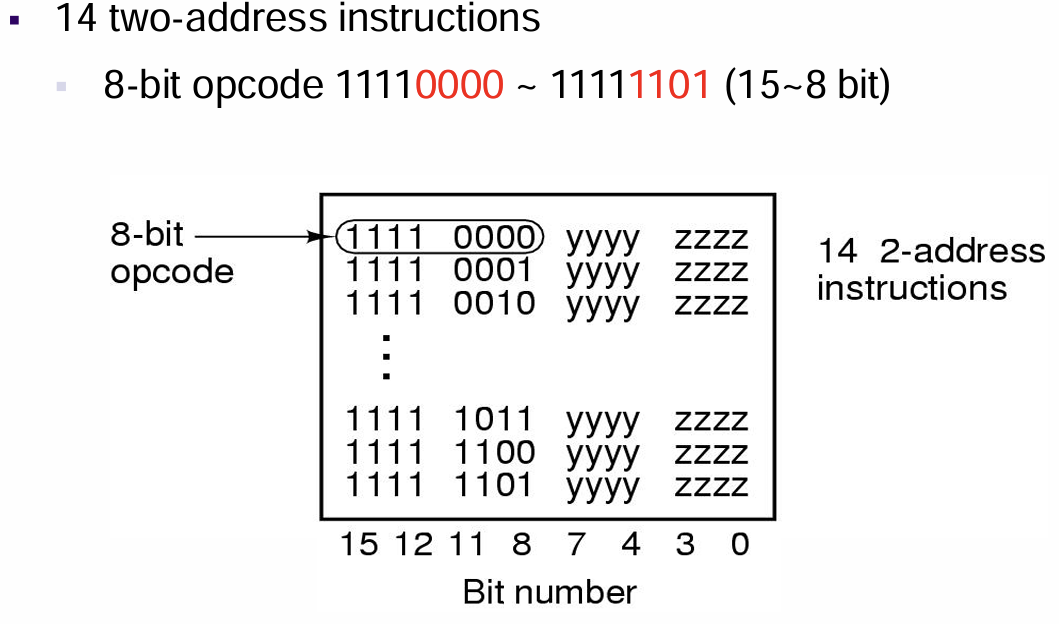
- $14$条二地址指令:采用$8$位扩展操作码,使用前$14$种译码作为不同的指令,余下的$1111\space1110$以及$1111\space1111$作为非二地址指令且非三地址指令的标识
- 为什么不只使用$1111\space1111$作为标识呢?因为这样就可以给单地址指令的数量多提供$1$bit的解码空间,使得其指令数量变成$2\times2^4=32$条而不是$2^4=16$条,而二地址指令仅仅损失了一条指令的空间就换取了单地址指令的16条指令空间的提升,这是极好的;并且双地址的操作需求并不多,而单地址的操作需求可能更多
- $31$条单地址指令:得益于多出来的$1$bit解码空间,单地址指令的数量来到了$32$,我们取用前$31$种情况作为指令,余下最后一种作为非单地址、非二地址、非三地址指令的标识(即无操作数)
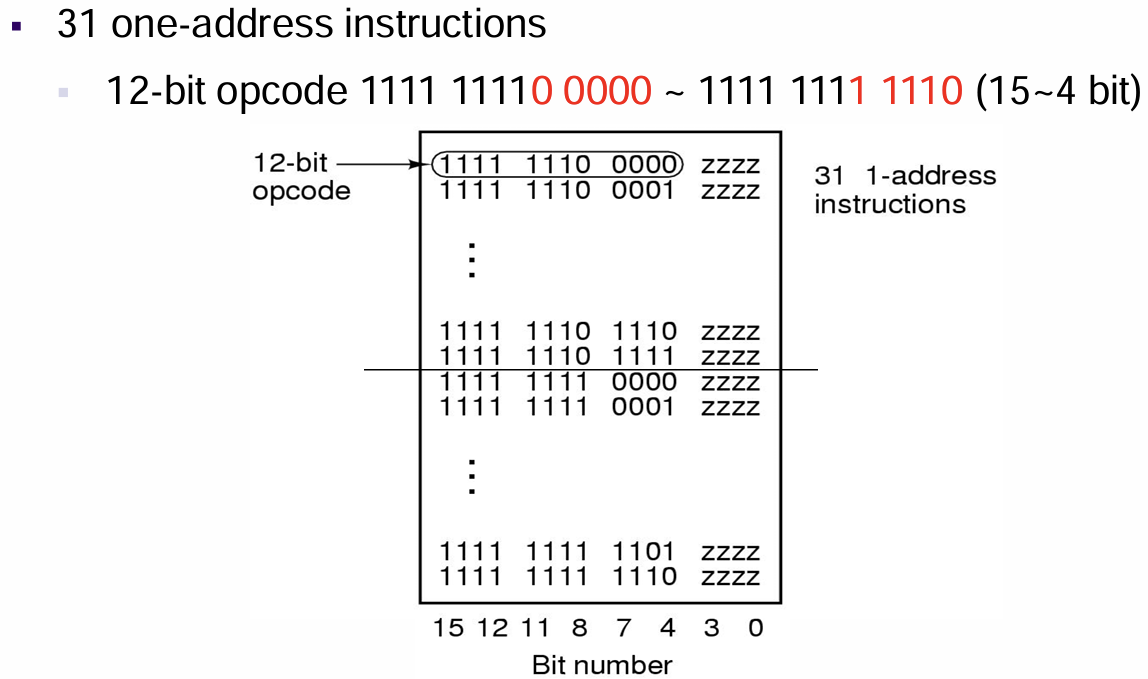
- $16$条无地址指令:$1111\space1111\space1111…$作为无操作数的操作码标识,拥有$16$个不同的指令,此时也无需像前面那样设置一个”非无操作数操作码”的标识,因为没法再增加操作码的位数来表示更多的指令了
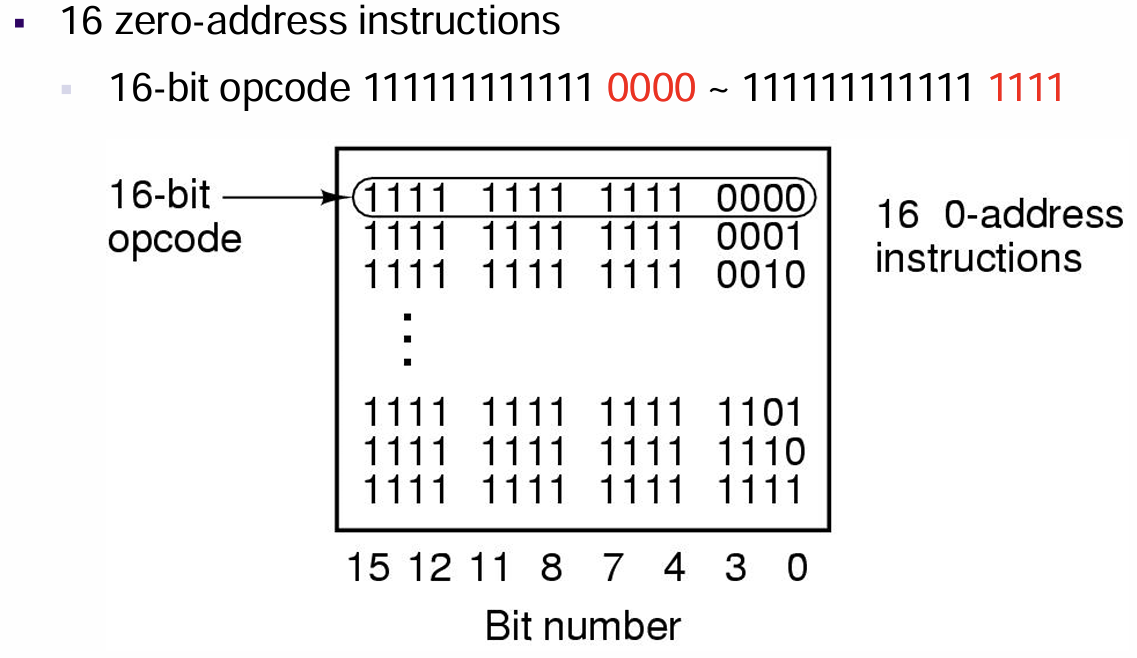
- 此时每条指令都是唯一的,译码就变得十分简单了
三、寻址模式
3.1 背景引入
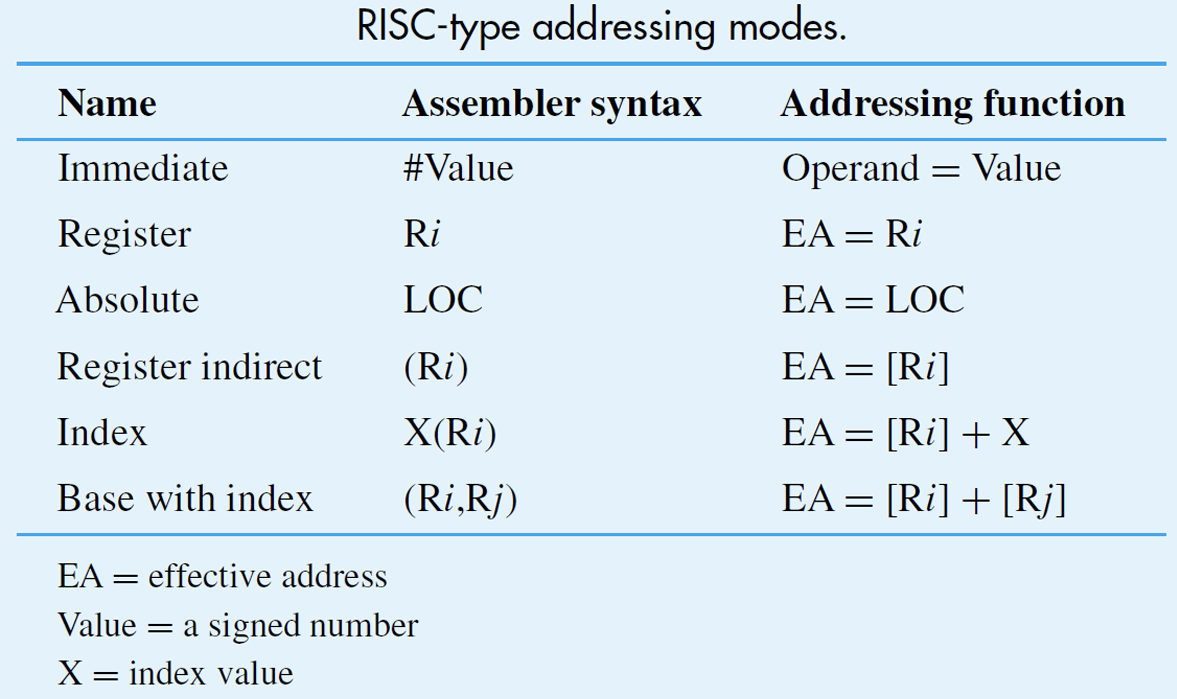
- 如何确定指令中Address Field指代的若干地址应当去何处寻址?是处理器寄存器、内存、还是IO设备?这就需要特定的寻址的规则来确定,即寻址模式(Addressing Mode)
- 下图是RISC指令集中规定的寻址模式(回忆在图灵完备游戏中简单实现过的四种模式)
3.2 立即数模式(Immediate Mode)
- 立即数寻址模式的指令(的对应二进制编码)被直接取用为操作数(二进制数),相当于将操作数直接放在了一系列的指令当中,比如
Add R4 R6 #200这个指令,就是将R6寄存器处的操作数和200(直接取用指令对应二进制编码数)进行相加操作后存放结果到R4寄存器处 - 使用方法就是直接写一个常量
- 优点:无需消耗内存来将指令映射到别的地址上再取操作数,而是直接将指令当操作数使用
- 缺点:只能当作常量来使用,且该常量的大小受指令长度(中的Address Filed的长度)限制
3.3 绝对/直接寻址(Absolute/Direct Mode)
- 绝对寻址模式的指令直接表示一个地址(而无需映射),操作数就被存放在对应的地址上,例如
Load R2 NUM这个指令相当于将地址NUM的二进制编码直接当作地址去内存中寻址,将对应位置储存的操作数加载到R2寄存器上
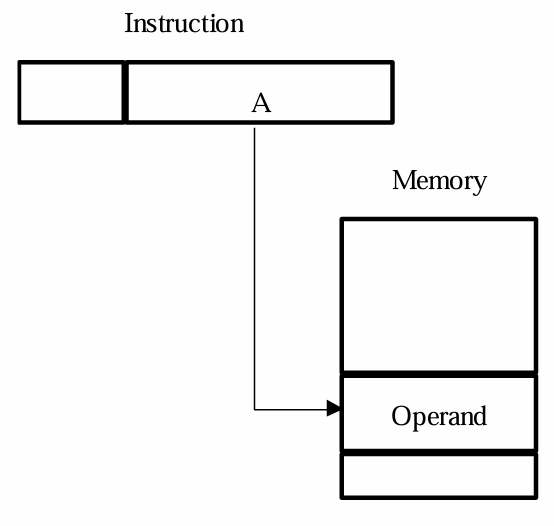
- 使用该模式就是直接使用一个访问一个已知的内存地址
- 优点:只会对应单个内存地址而不会出现特殊的转换
- 缺点:固定的寻址地址导致张开的地址空间有限,而内存地址的数量十分庞大
3.4 间接寻址(Indirect Mode)
- 间接寻址仅在CISC的处理器中使用
- 间接寻址模式的指令会先使用其内存储的地址找到内存中的一块空间,将此空间处存储的内容即实际需要的操作数的地址取出,然后再找到实际的操作数并取出(下图的
EA=[A]意思是用EA表示的目标操作数的有效地址B等于地址A处的内容)
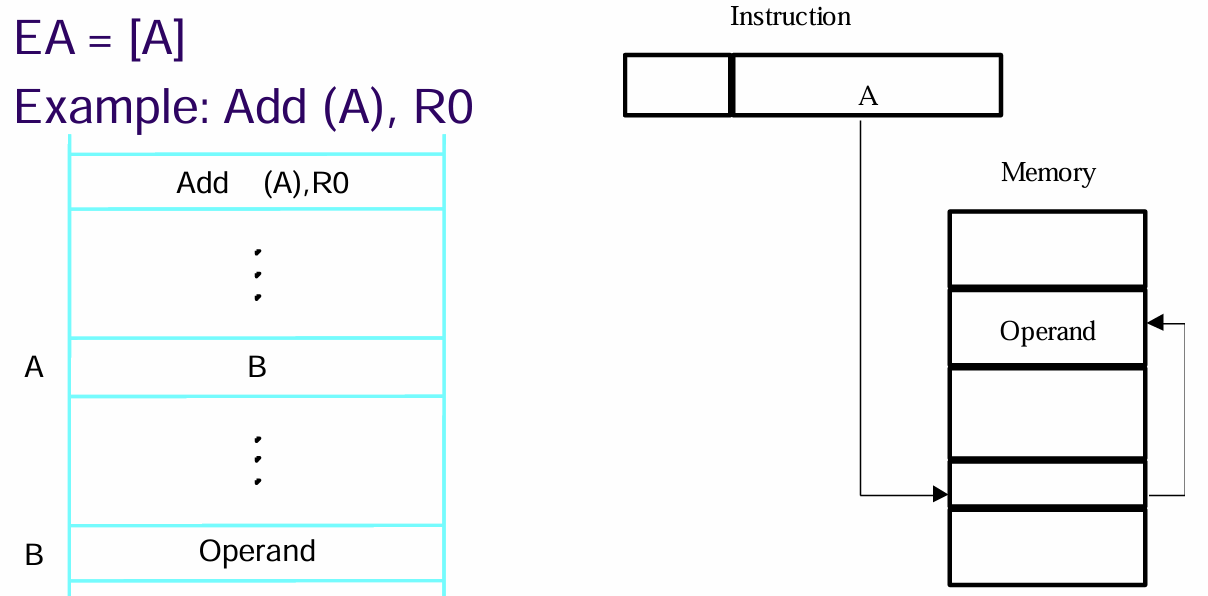
- 使用该模式时,指令中的(一部分)地址是间接给出的,需要经历两次寻址的步骤
- 优点:
- 当操作数地址改变时,只需修改间接地址指示器的单元内容,而不必修改指令
- 地址空间大,若指令中的地址位数为$n$,则使用直接寻址在不改变指令的情况下只能固定对应$2^n$个内存位置的操作数,而间接寻址同样对应$2^n$个字长为$m$的内存Word,但可通过修改该Word来扩大地址空间,间接寻址地址空间理论覆盖范围为$2^{nm}$
- 缺点:
- 需要使用两个地址索引来拉取操作数,增加了时间复杂度
- 每个被间接寻址的操作数占用的空间翻倍,占用主存储器单元多
- 优点:
- 还存在一种多级间接寻址模式,通过$1$bit来标识该内存Word是否是需要的操作数,否则继续在内存中跳转,直到找到目标操作数
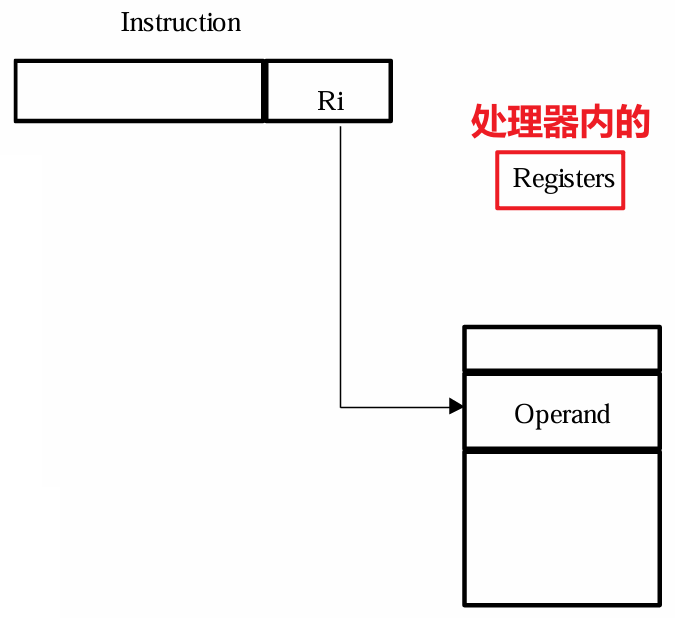
3.5 寄存器寻址(Register Mode)
- 直接和间接寻址都是在内存中寻找操作数,而寄存器寻址则是直接在处理器内部的寄存器上拿取操作数进行所需的操作
- 优点:
- 由于寄存器很少,所以其所需要的地址不像在内存中寻址所需的地址位数那么多
- 无需像在内存中寻址那样需要地址索引,减少了拉取操作数的时间复杂度
- 缺点:
- 地址空间十分有限
- 优点:
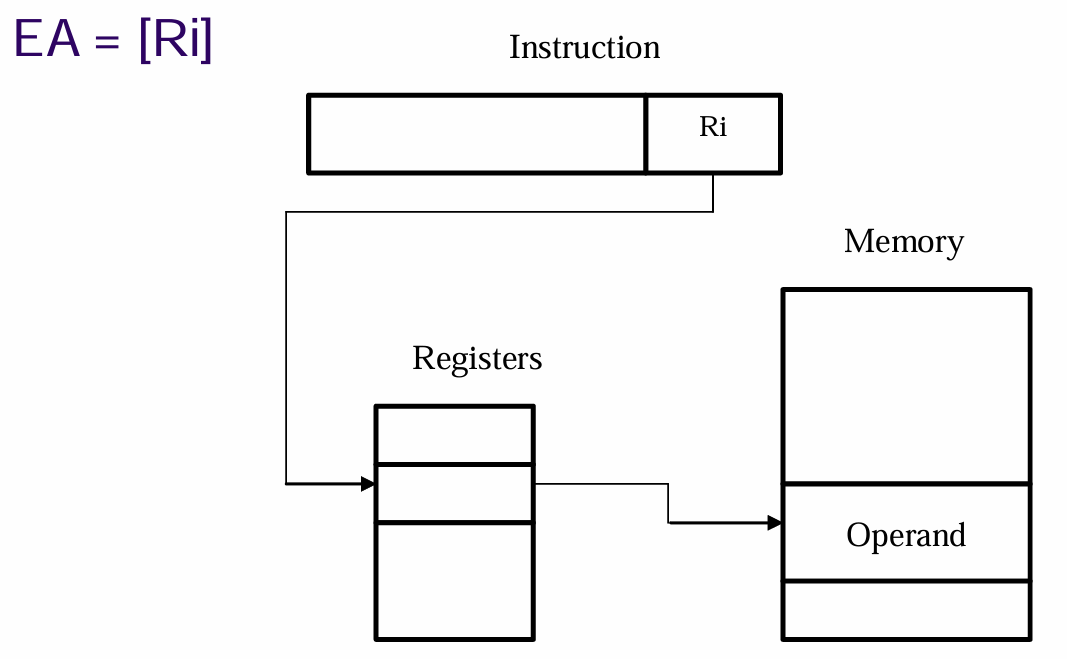
3.5 寄存器间接寻址(Register Indirect Mode)
- 寄存器间接寻址类似间接寻址,但中间步骤是寻找存储在寄存器中的内存地址
- 尽管其扩充的指令空间大小不如间接寻址(寄存器存储的位数比内存Word的位数小)
- 但由于访问寄存器比访问内存更快,所以寄存器间接寻址比间接寻址有更低的时间复杂度
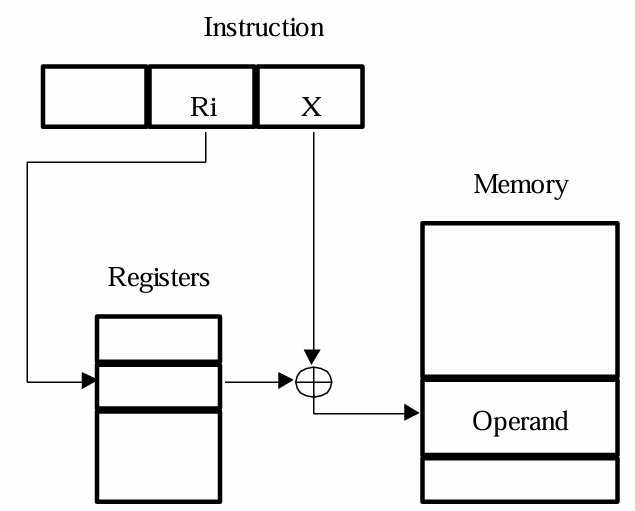
3.6 变址寻址模式(Indexed Mode)
变址寻址模式与基址寻址模式(Base Addressing Mode)十分相似,此处不展开对比
- 变址寻址模式指的是对基地址$X$加上索引$Ri$,即以$X+[Ri]$来映射得到目标操作数所在的地址的寻址模式,用$X(Ri)$表示
- 其中基地址$X$是一个存储在指令中的常量值,或者是存储在特定寄存器中的值,相当于数组的首地址
- 而索引$Ri$则存储在Index寄存器中,是可变的,通过不同的索引值可以访问以$X$为首地址的数组中的元素值
- 变址寻址模式还有两个变种形式
- 当基地址可变时,我们就需要使用一个基地址寄存器(Base Register)来存储基地址,此时使用$(R_j,R_i)$来表示,有效地址的计算方式同理为$EA=[R_j]+[R_i]$
- 在上面的基础上,若我们需要一个额外的偏移常量$N$来计算地址的话,该寻址方式就表示为$N(R_j,R_i)$,有效地址为$EA=[R_j]+[R_i]+N$
3.7 相对寻址(Relative Mode)
- 相对寻址使用PC代替$Ri$作为变址寻址的索引变量,有效地址$EA=[PC]+X$
四、习题训练
4.1 变址寻址

4.2 分支指令之循环
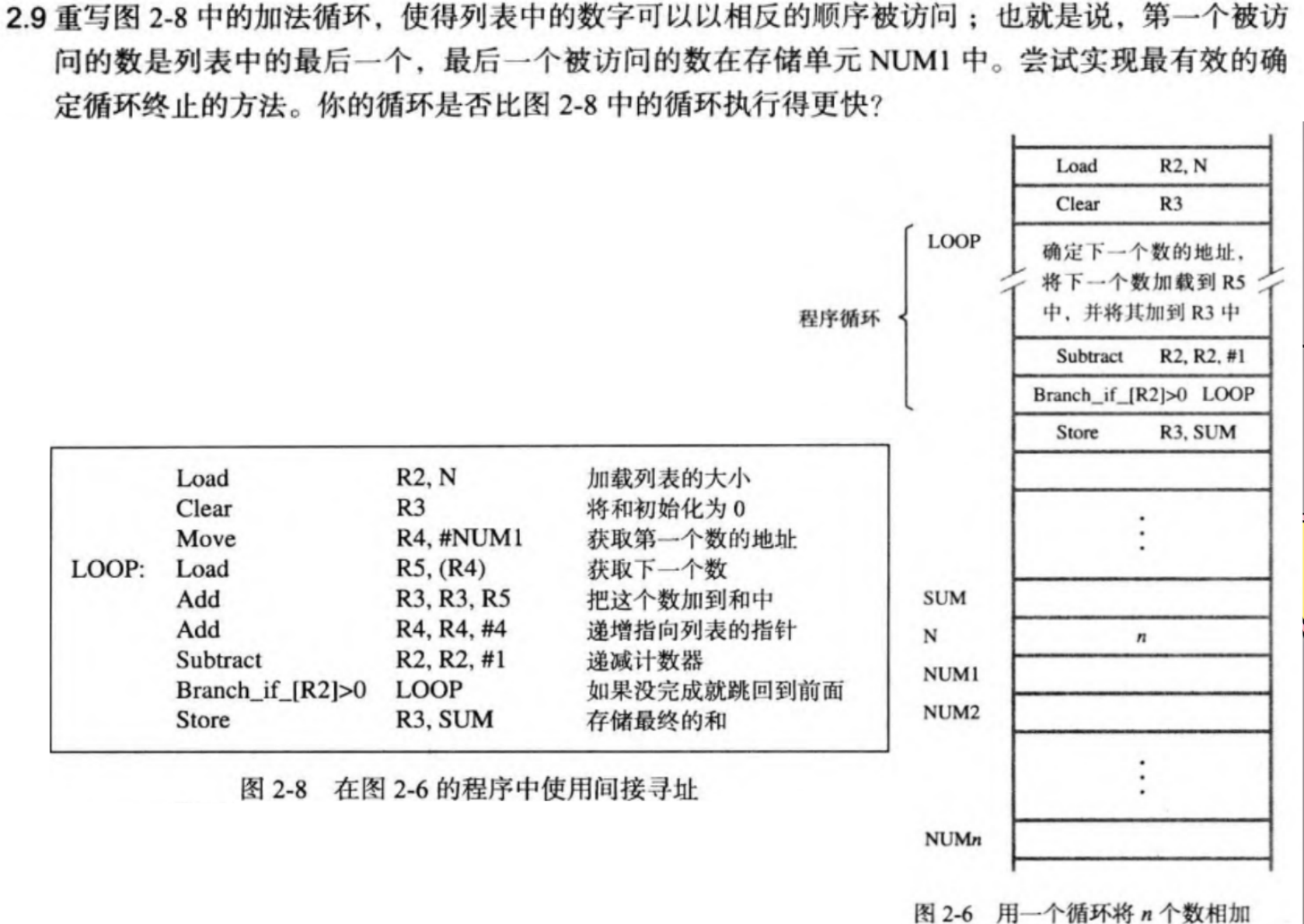

4.3 指令格式设计例一


4.4 指令格式设计例二

本文由作者按照 CC BY-NC-SA 4.0 进行授权