详解Cache的映射策略与读写操作
从Cache的简单介绍引入,详细介绍三种不同的映射策略以及读写策略的相关概念
详解Cache的映射策略与读写操作
一、Cache的作用
- Cache是基于SRAM的快速小容量存储器,完全由硬件自动管理而无需上层的软件进行管理
- Cache充当CPU和主存之间的缓冲区(Buffer)以提升访问速度并降低成本
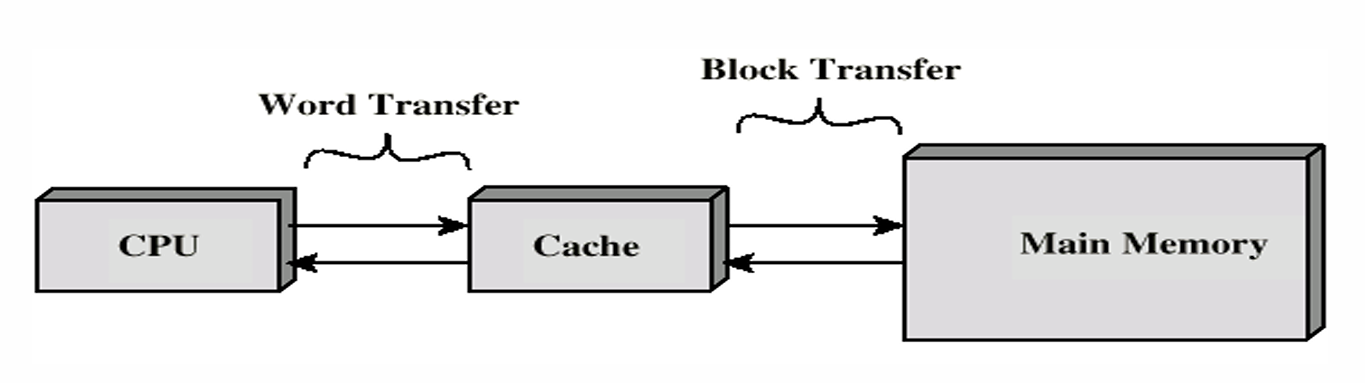
- Cache-主存系统完全由硬件实现而无需软件,软件只能调用其功能
二、映射策略
2.1 关于映射策略
- 映射策略(Cache Mapping Schemes)指的是在拷贝Block时可以将其放在Cache的何处,其还需要将处理器传入的主存地址转化为Cache地址(如果CPU传入了一个主存内某个Word的地址,但是这个Word已经存在于Cache中了,相同的主存地址无法用于访问Cache)
- Cache从主存中以块(Block)为单位进行读取
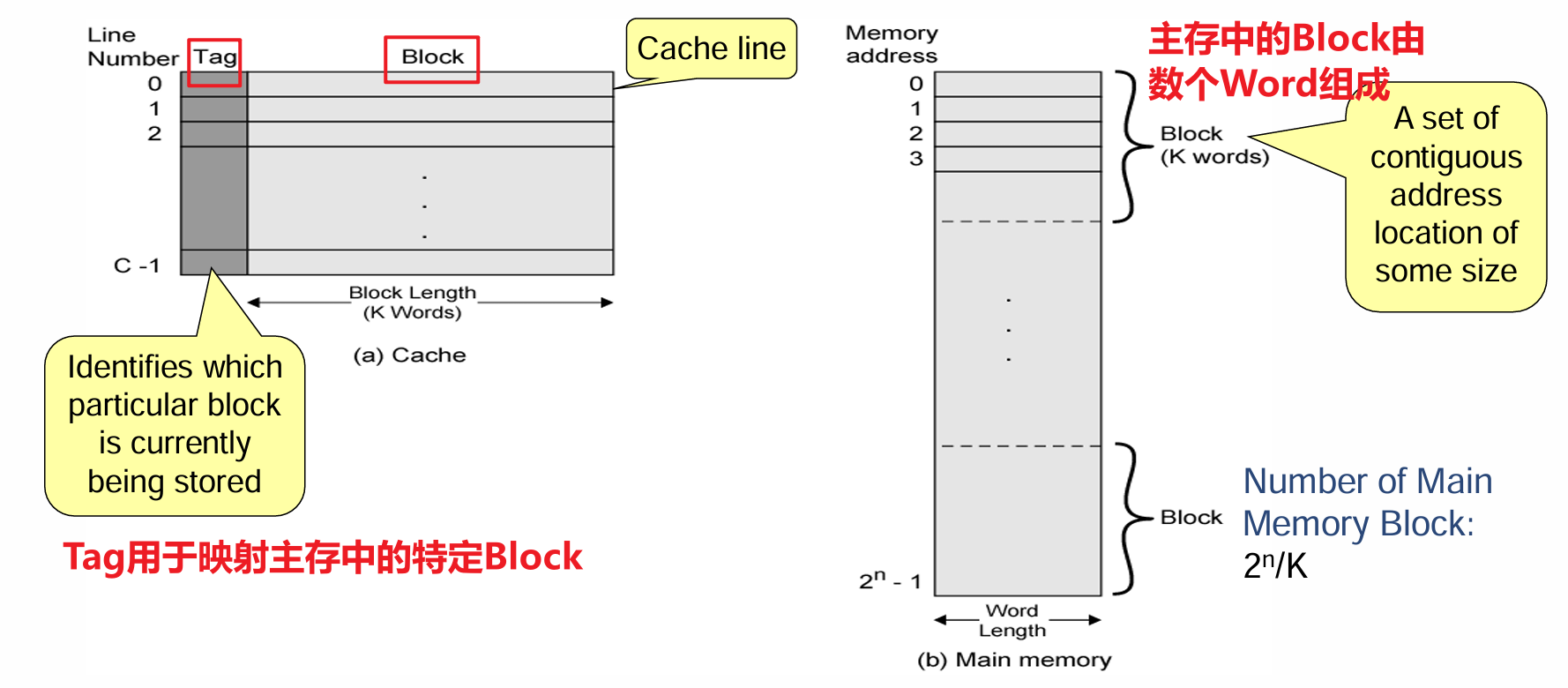
- Cache的每一行被设计为正好能存储一个Block的容量大小,为了方便讨论:
- 将Cache的每一行(共$m=2^r$行)标记为$L_i$
- 将主存内的每个Block(共$n=2^s$块)标记为$B_j$
- 每一行存储的Word(CPU每次访问的就是某个字)数等于每个Block的字数$k=2^w$
2.2 直接映射
优点:实现的复杂度低且便宜 缺点:映射固定,当连续取用多个指向同一Cache行的Block时会导致频繁的访问Miss,频繁的擦写会导致数据复用率变低
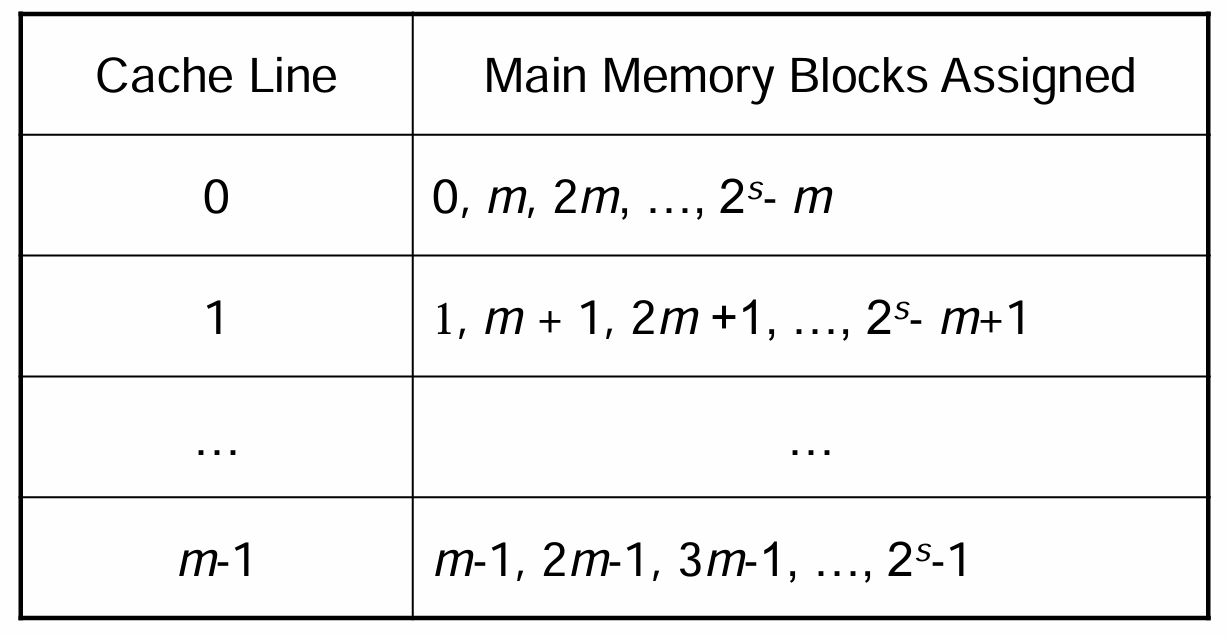
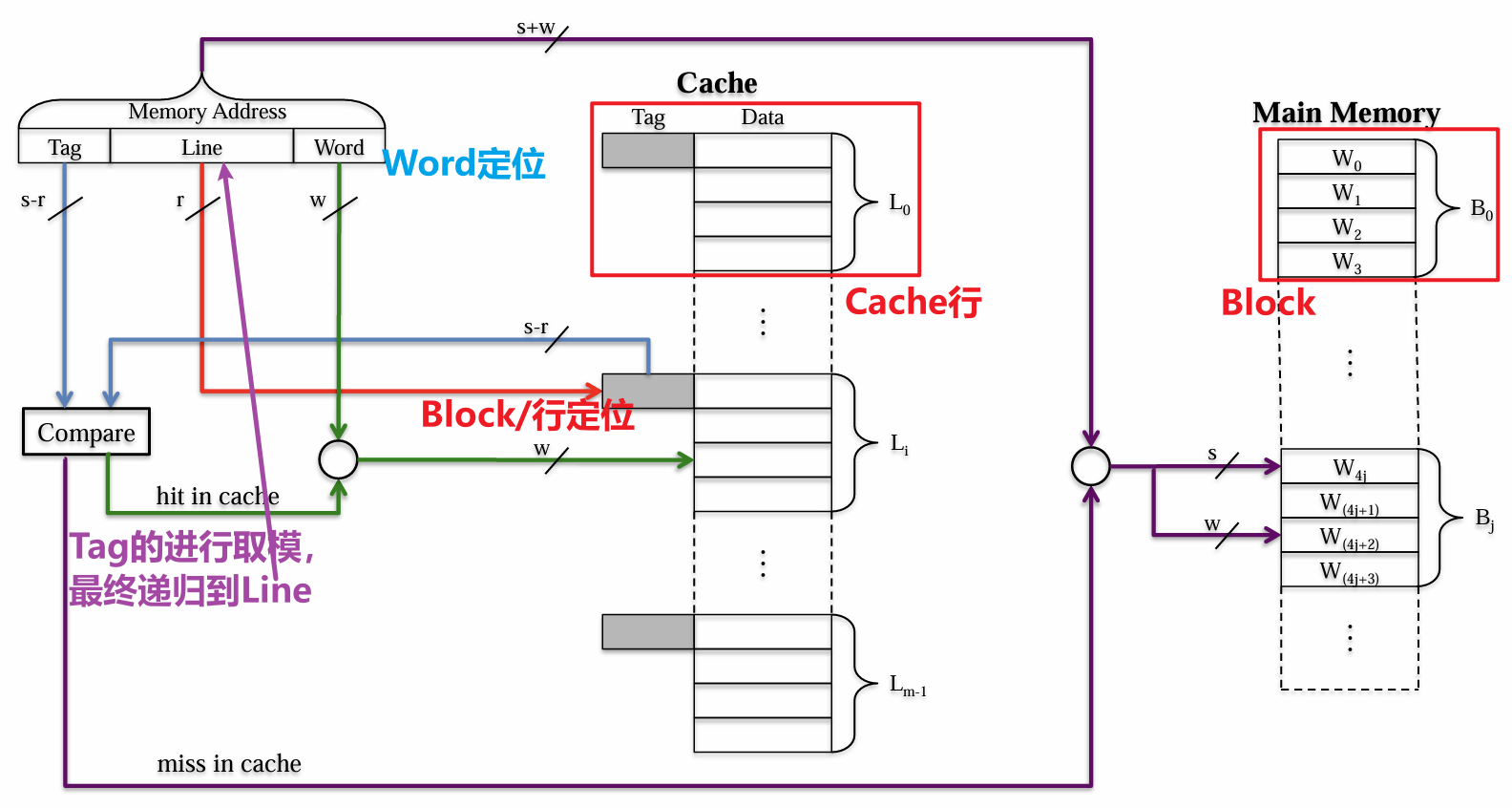
- 直接映射(Direct Mapping)指的是每个主存Block仅唯一对应一个Cache行,我们将Block的索引对Cache的总行数取模,这块Block就对应Cache中的这个取模结果的索引行处(即$i=j\space\%\space m$)
- 由于是取模运算,Block数量$n$是远大于Cache行数$m$的,所以每一行是可以对应多个Block的(但每个Block依然对应唯一的某行),如下表所示
- 一个用于取用主存中某Block的某Word的地址包含两个部分(高位MSB与低位LSB),其中MSB共$s$bit用于解码定位唯一一个Block(总块数$n=2^s$),其被分为两部分
- 最高位
Tag:$(s-r)$bit,是Block的$s$bit解码定位中的高位$(s-r)$bit部分,将其单独拿出看是无意义的,其被当为一个独特的标志,用于唯一指向特定的某组$m$个Block的族群(若全为0则说明这个Tag指向的族群是主存中的前$m$个Block,若非则指向特定的族群,族群总数视$n/m$而定) - 中间位
Line:$r$bit,是Block的$s$bit解码定位中的低位$r$bit部分(将整个$s$位编码对应的$n$个Block进行对行数$m$的取模后,将被储存到相同行的地址的Line标签是一样的),用于解码定位Cache中的某一行(总行数$m=2^r$) - 最低位
Word:$w$bit索引编码,用于解码定位一个Block中的某个字(总字数$k=2^w$)
- 最高位
Tag+Line共$s$位编码用于在主存中寻址特定Block,而由于Cache比主存小,所以仅需Line部分的编码在Cache中寻址特定的Line/Block(这也是将$s$位编码拆分开来的原因),由于Line并非完整的$s$位编码,所以此时通过Line找到的Line/Block并不能被精准对应到主存中的特定一个Block,仅能对应到某一块区域的一组Block(即余数相同的一组),所以还需要再通过Tag进行比对确定是否Hit
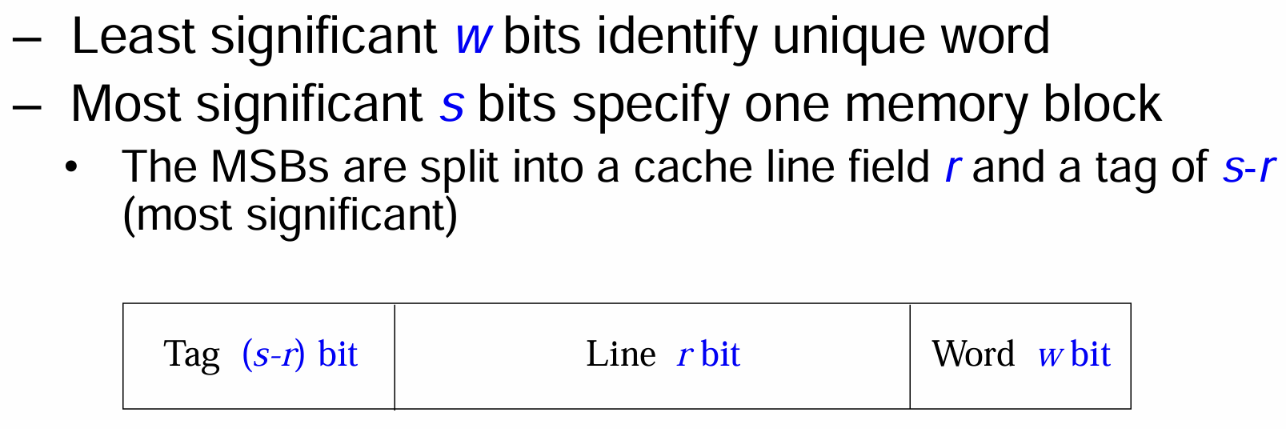
- 此处主存地址编码规则如下图所示,该编码规则是为直接映射所定制的
- 每次寻址先对
Line进行处理,找到Cache中的对应行,同时获取了该行储值的Tag - 然后对传入的
Tag进行与上述已有Tag的对比,若相等,则说明访问Hit了,此时结合传入的Word从先前找到的Cache行中取得对应Word,任务完成 - 若
Tag不相等,则说明访问Miss了,此时需要将传入的地址整体拿来,用于定位主存中对应的Block的对应Word,并将其存入正确的Cache行中
- 每次寻址先对
2.3 全相联映射
优点:解决了直接映射的缺点 缺点:在Cache中查找
Tag的电路复杂度十分高
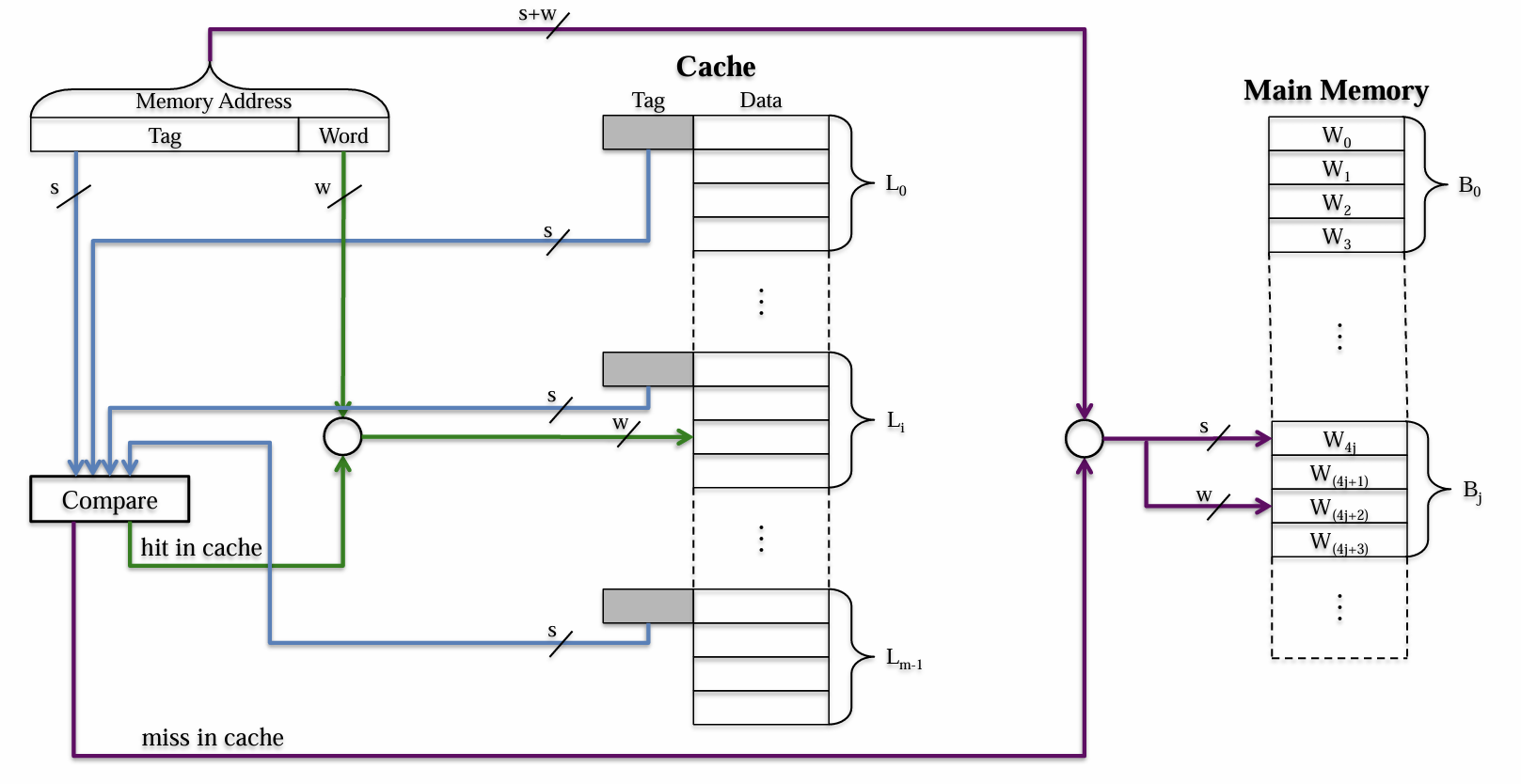
- 全相联映射(Associative Mapping)指的是主存中的所有Block都可以被载入到任意Cache行中
- 为这种映射设计的主存地址编码结构如下
Tag:高位的$s$bit用于映射主存中的特定Block(无需像直接映射般再次细分两部分)Word:低位的$w$bit用于映射Block的$2^w$个字中的特定Word

- 当CPU传给Cache一个访问地址时,Cache会先将自己的每一行的
Tag与传入的地址的Tag做对比,若Hit了,就再取用传入的地址的Word字段来锁定目标字传回CPU;若Miss了,就通过传入的地址的Tag去主存上寻址Block与Word,然后再将找到的Block存放在Cache中
2.4 组相联映射
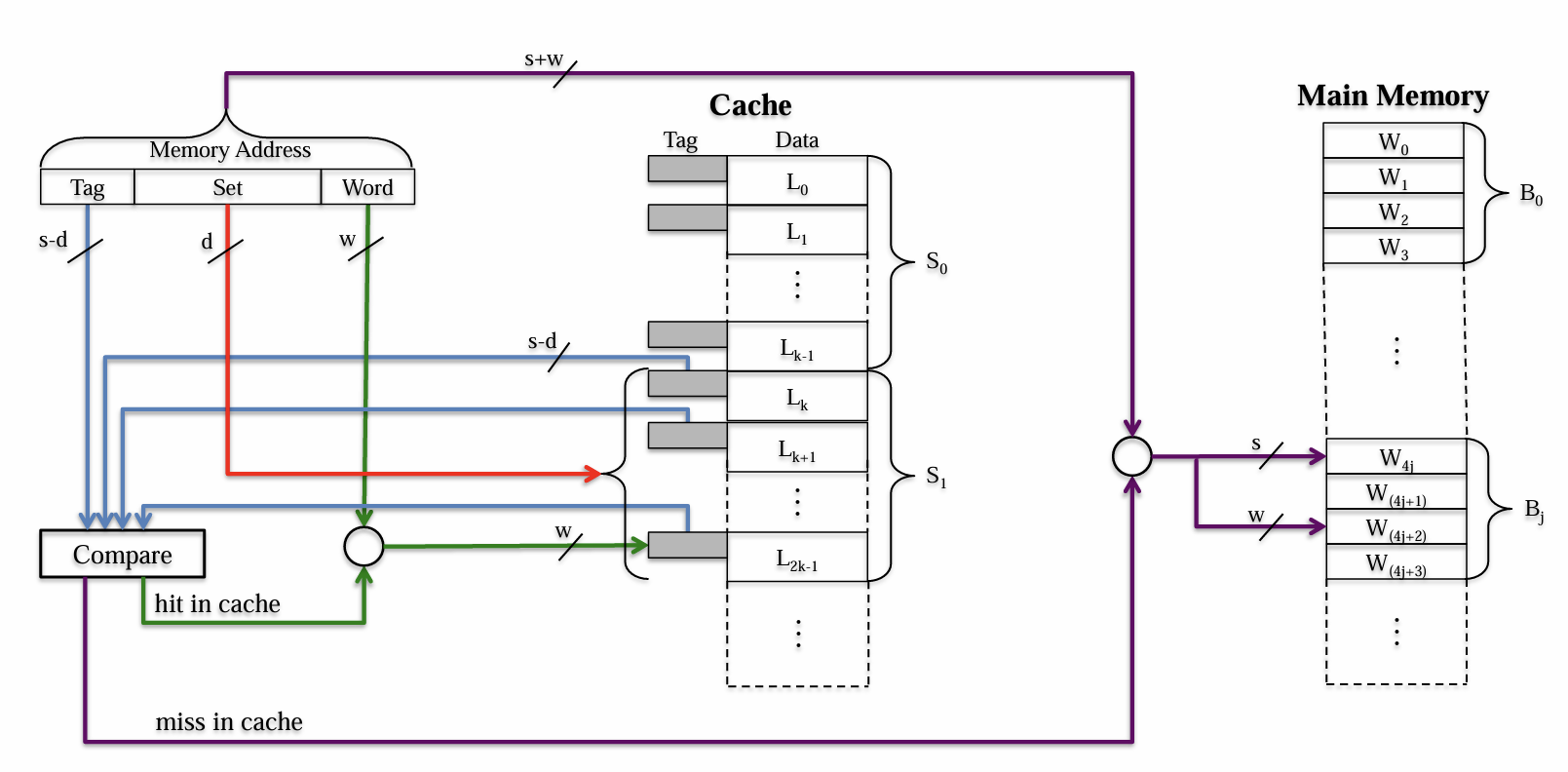
- 组相联映射(Set Associative Mapping)是一种混合了直接映射与全相联映射的映射策略,这个策略将Cache的Line划分为若干组,每一个Block会被映射到唯一一个Line的组内,其可以被放到该组内的任意一行
- 假设我们将Cache的所有$m=2^r$行分为$v=2^d$组,这样每一组就拥有$t=\frac{m}{v}=2^{r-d}$行,我们将这样的一个映射称为$t$-Way的分组关联映射;第$j$个Block会被唯一映射到索引为$j\%v$的组,其可以被放入该组内的任意一行
- 当$v=m$时,$t=1$,退化为Direct Mapping
- 当$v=1$时,$t=m$,退化为Associate Mapping
- 这种映射的主存地址编码结构与直接映射的类似,高位共$s$bit用于解码锁定主存中的Block,其内被分为
Set用于锁定组别、Tag仅用于标记组别信息,Word用于锁定Block的WordTag:$(s-d)$位,直接可以精确对应到Cache中的特定行Set:$d$位,比Line的$r$位更短,所以一个Set字段可以索引出多个(即特定的一组)在地址编码低位Word的$w$位的左侧的$d$位相同的Cache行Word:和前两种映射一样,定位特定Cache行中的

- 为了加深对于地址设计的理解,我们可以参考以下例题

- 图示如下,CPU传地址给Cache,后者先用
Set锁定一组Cache行,然后将这一坨Line的所有Tag与传入的地址的Tag一一作比较,Hit了某个行就可以继而直接通过Word锁定对应行中的字
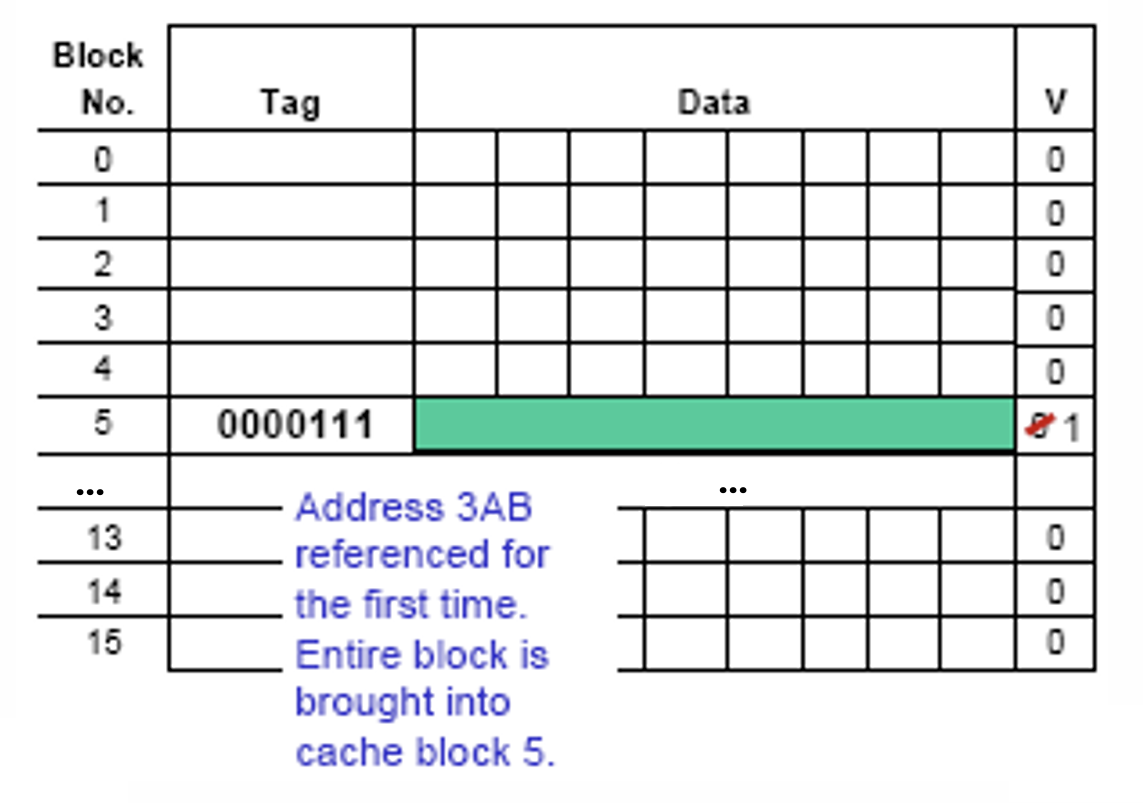
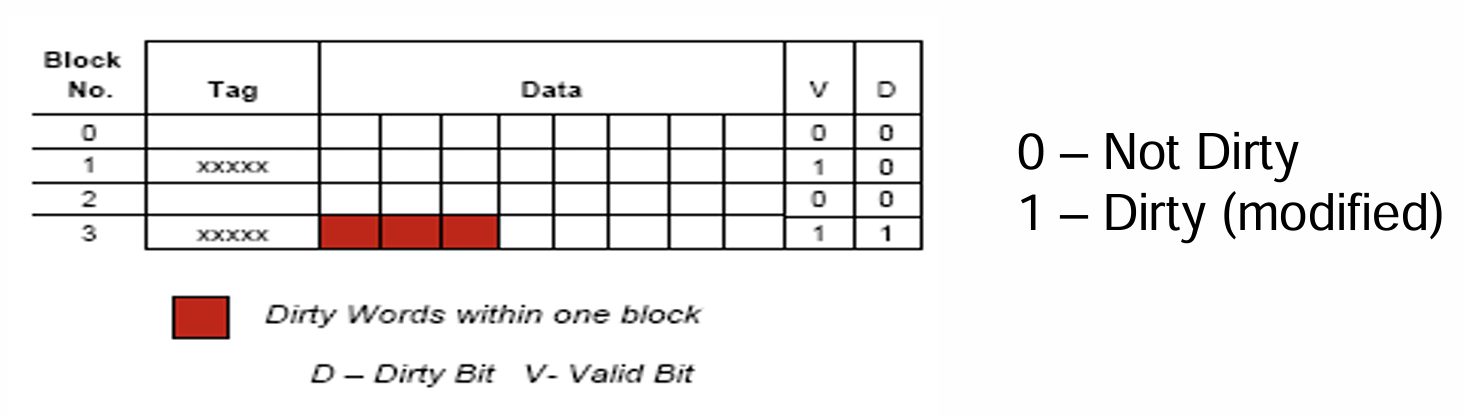
2.5 Valid Bit
- Cache中的每个Line都受一个1bit的Valid Bit所控制,表示该Line存储的Block的数据是否是有效的(0无效,1有效) ,所以当Cache刚通电的时候,其内视为没有存储任何有效数据,所有Line的Valid Bit均被初始化为0
- 每当主存中的一个Block被拷贝到Cache中的某Line上时,该Line的Valid Bit被标记为1
2.6 替换算法
- 直接映射:主存的中每个Block都唯一对应一个Cache的Line,没有选择,每次传入新的就直接替换掉其该去的地方即可,没有专门的替换算法(Replacement Algorithm)
- 全相联映射与组相联映射:当Cache存满了,此时再从主存取用新的Block的时候据需要替换算法来选取被替换的Line来存放该Block
- LRU(Least Recently Used)算法:选取Cache中最长时间没被访问过的Line
- FIFO:每当一个Line被存入新Block的时候(即Valid Bit被更新为1时),将其放入一个队列,以先入先出的方式取用被替换的Line
- 随机:随机选取一个Line用于替换新的Block
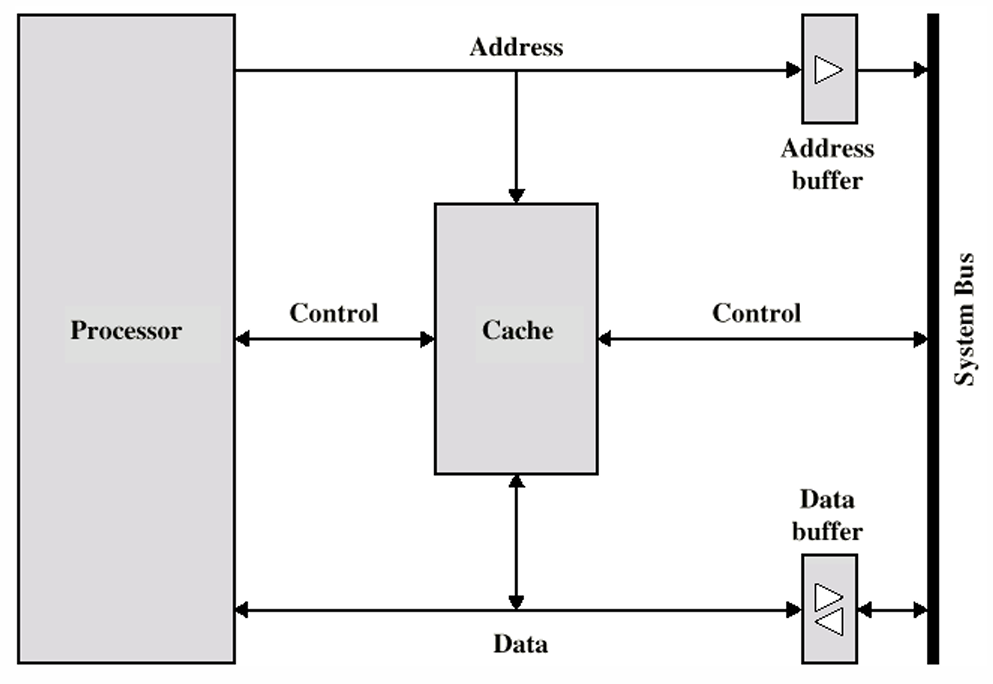
三、读操作
- 处理器(CPU)不需要显式地知晓Cache的存在,其只需要提供一个主存的Address来请求寻址对应内存,而Cache的控制电路会判断被需求的Word是否存在于Cache中
- 在层次结构章节笔记中我们了解过Buffer的访问方法以及局部性原理,Cache作为主存的Buffer自然也是一样
- Read Hit:直接将目标推送给处理器
- Read Miss:有以下两种处理方式
- 1、将主存中的对应Block的数据读取到Cache之后,再将Requested Word传回
- 2、Load Through/Early Restart,即在读取Block的同时,就将Requested Word传回
四、写操作
4.1 透写Hit
- 透写(Write Through):发生对某个Word的写操作时,Cache和主存的内容被同时修改
- 优点:
- Cache和主存的数据是即时同步的
- 缺点:
- 因Cache和主存的写入速度不同,所以快的要等慢的,导致写的速度降低
- 因所有指令都用的是同一根数据总线来传递,写的时候若还存在别的请求比如读请求,该请求就会被延后,导致整体的运行速度降低
- 优点:
4.2 回写Hit
- 回写(Write Back):每当发生了某个Word写的修改的时候,先只更新Cache中的对应数据,并对该Word使用1bit的数据进行标记(Dirty or Modified Bit)
- 优点:
- 无需等待主存的写入,所以比Write Through更快
- 若修改了同一个Block中的多个不同Word,则在更新时会被同时写入主存,而Write Through则需要每更新一个Word就需要将其同步到主存的对应Block中去
- 缺点:
- Cache与主存中的数据无法即时同步
- 每个Word需要的标记位都额外增加了1bit,导致整体的空间复杂度增大
- 优点:
4.3 Miss
- 上述对透写与回写操作的讨论是建立在写的操作在Cache中Hit的情况,而当Miss时
- 透写:直接将主存中的目标Word修改掉,而省去了将Block拷贝到Cache的步骤
- 回写:先将目标Word所在的Block拷贝到Cache,然后以原本的方式执行回写
五、命中率
- 命中率顾名思义,总访问(读或写)次数中Hit次数的占比

- 通过Hit率与Miss率,我们可以计算出每次操作的平均耗时

六、层次结构
- 在讲解Cache的层次结构前,设想一个Unified的Cache,其指令和数据都混合存储在一起,由于二者的用途差异,这种设计会导致大量的访问Miss,所以一般会将二者分离以降低频繁Miss导致的高时间复杂度
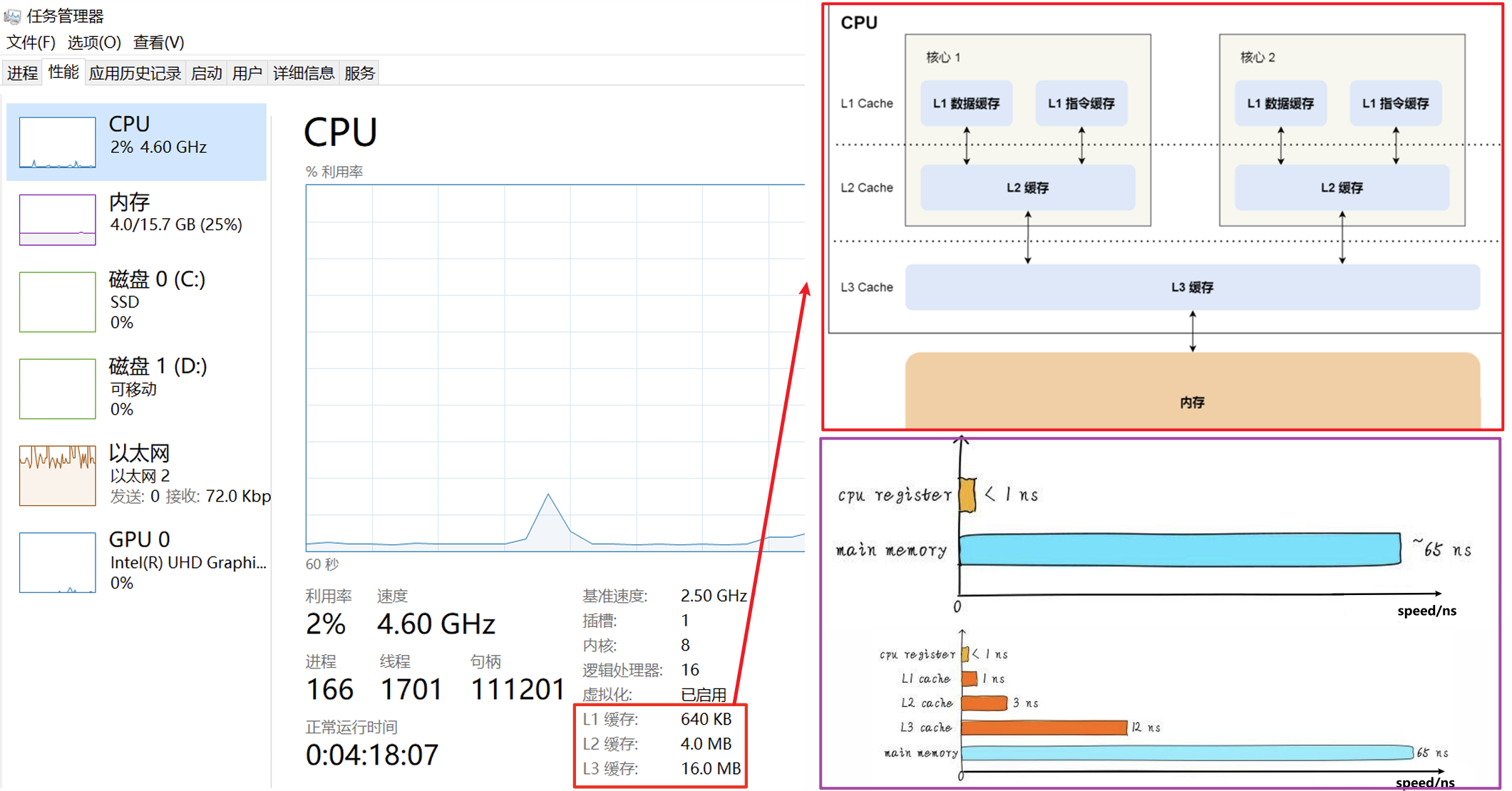
- 我们回忆存储器有分级的层次结构(Hierarchy),其按照存储器的容量和访问速度形成金字塔形的层次,而现代计算机中的Cache也大都采取类似的多层级的结构
- Level 1(L1)Cache
- 处于CPU内部(即层次结构上层),访问时间通常为4ns左右
- 容量通常很小(8KB~128KB)
- 分为指令和数据Cache两个部分
- Level 2(L2)Cache
- 在CPU外部(即下层),但与CPU通过高速总线相连,访问时间15ns~20ns
- 比L1容量更大(256KB~若干MB)
- 是Unified的,而不区分指令和数据Cache
- Level 1(L1)Cache
- 以英特尔的商业CPU为例
七、习题训练
7.1 作业习题
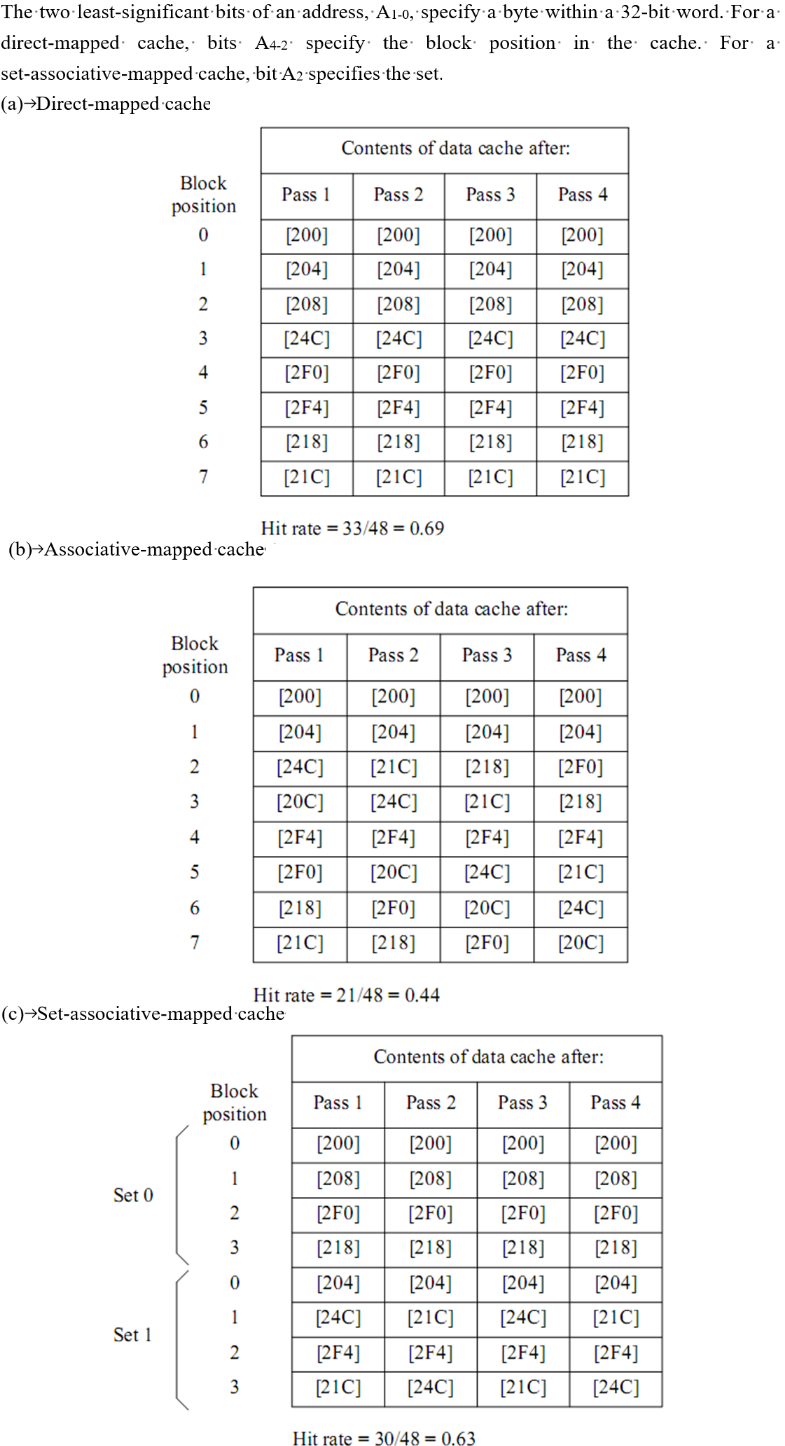
- 下面的题目综合了三种映射策略、LRU替换策略、命中率等知识,对于十六进制地址,需要将其先转化为二进制编码,然后将这$12$bit的二进制编码按照不同映射策略的编址格式进行意义理解
- 与前面笔记中不同的是,此处是每个Cache小Line容纳一个Word,Word又分为若干Byte,类比前文中的Block中有若干Word
- 然后我们再来分析此处题目的意思,每个小Line内容纳1个Word,每次处理器寻址的是精确到比特的数据,从主存中查找对应Byte,并将其所在Word拷贝到Cache中的某个Line上
- 所以十六进制地址转化的二进制地址的意义就很明了了,最低2bit是用于查找4字节中的特定字节的,而相邻的高位则视映射策略不同而含义不同,对于直接映射,倒数第三、四、五共3bit的编码是映射Cache中的8个Line的编码

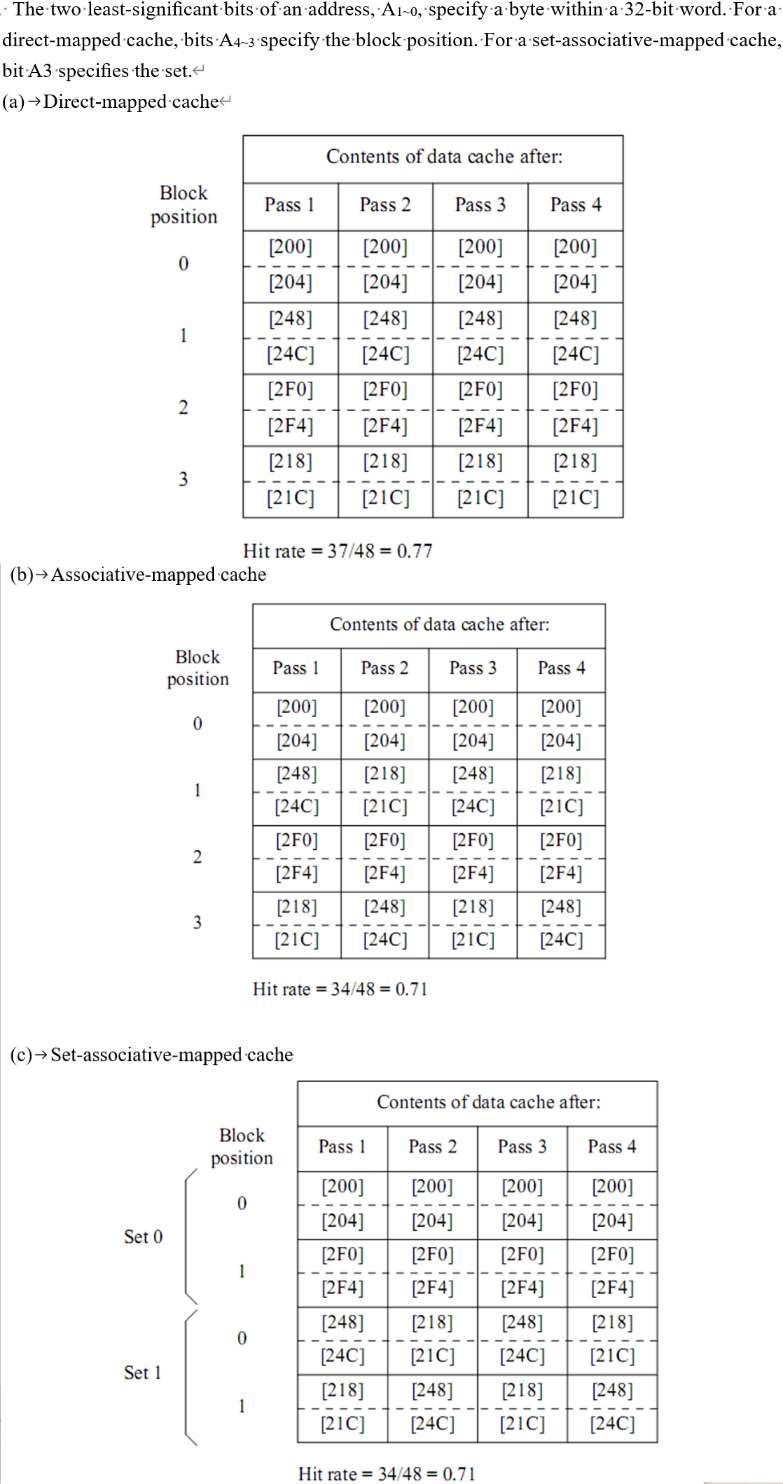
- 下面是一个变式,道理是一样的

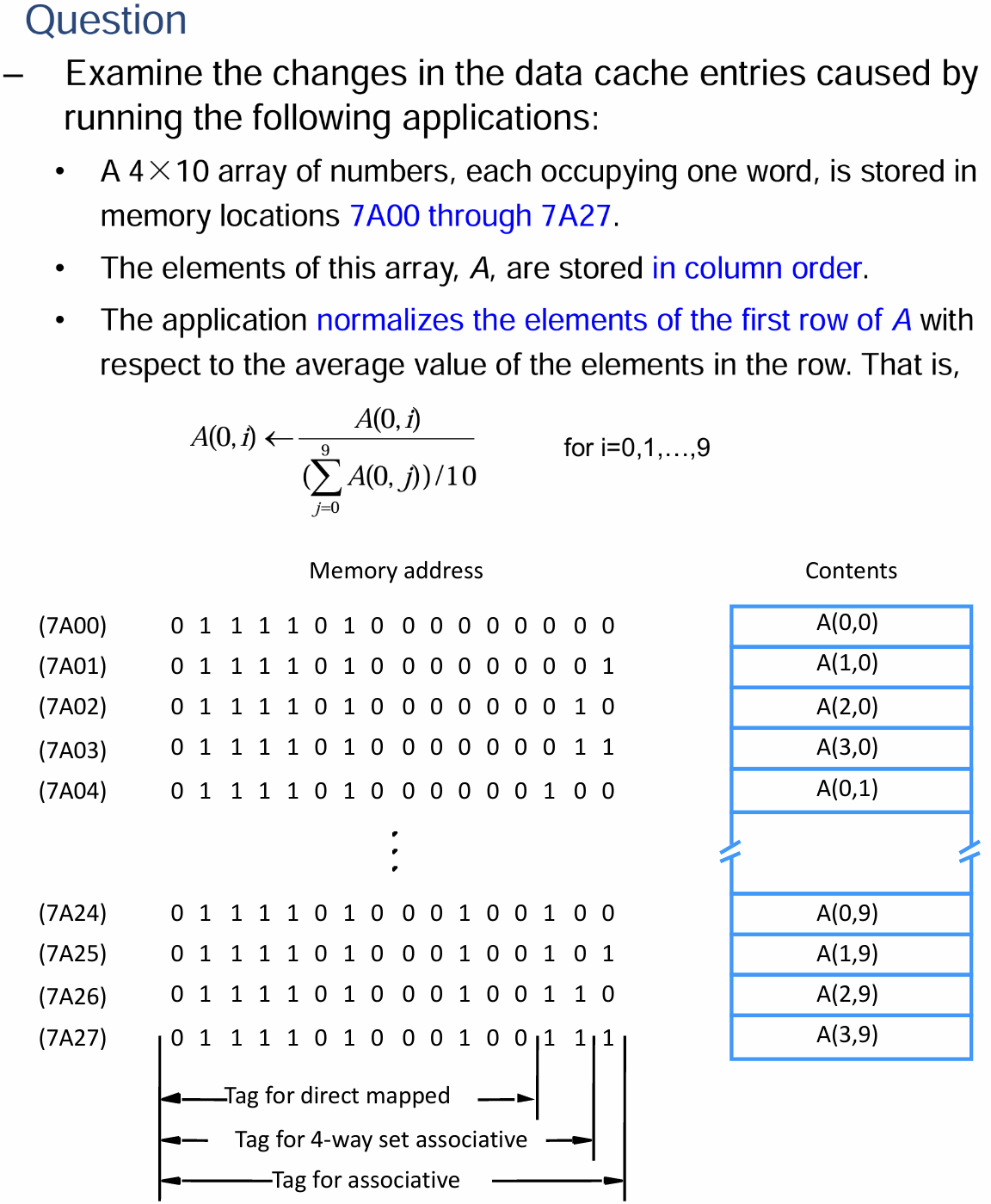
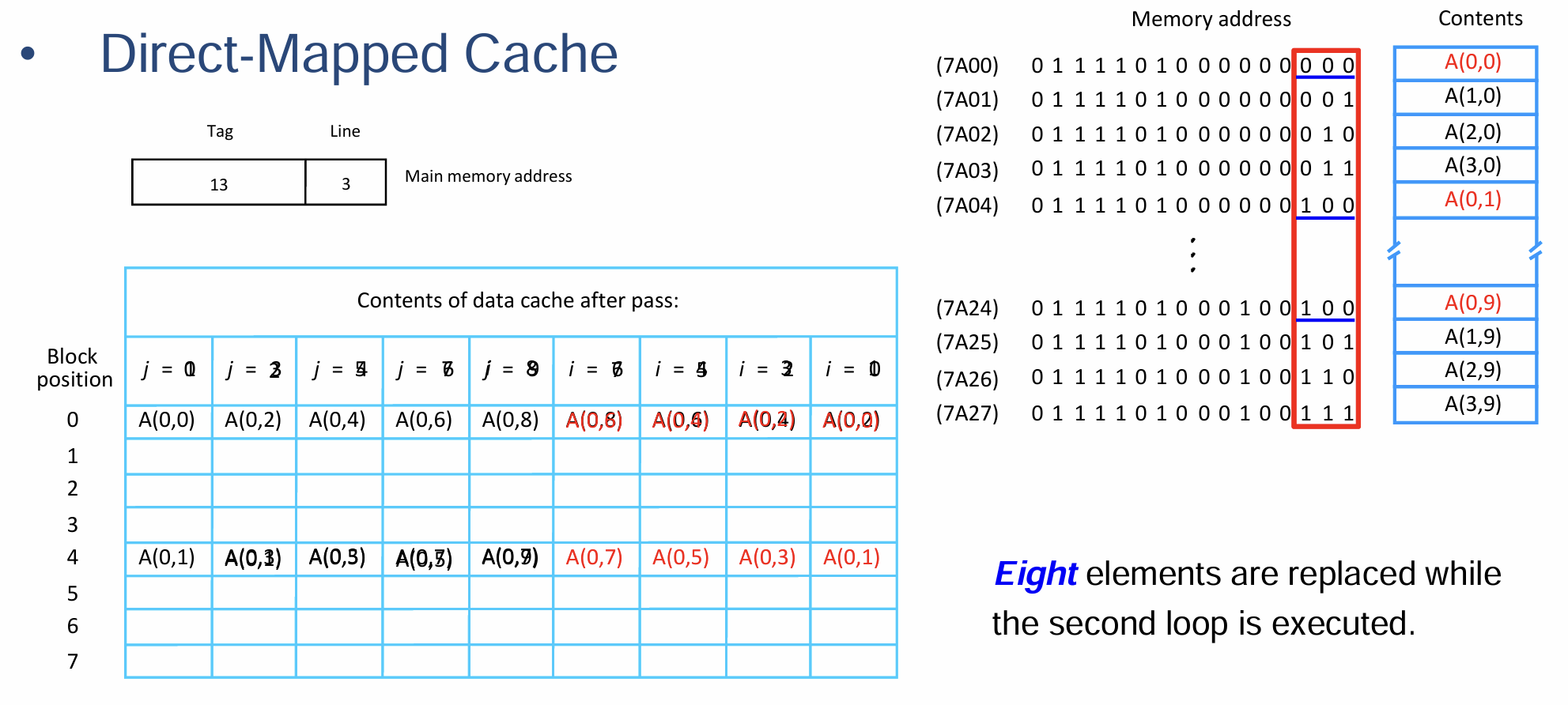
7.2 课件例题
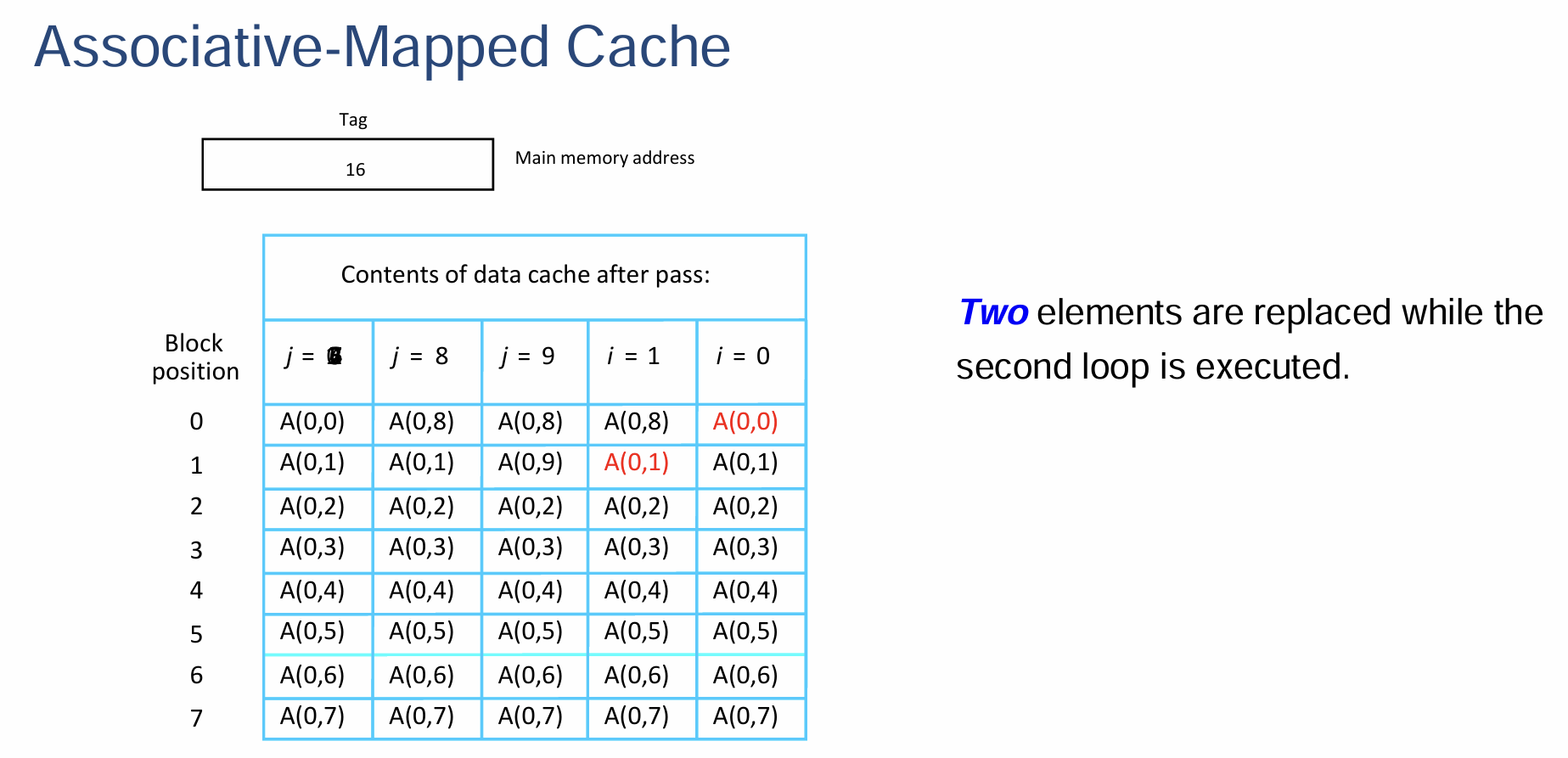
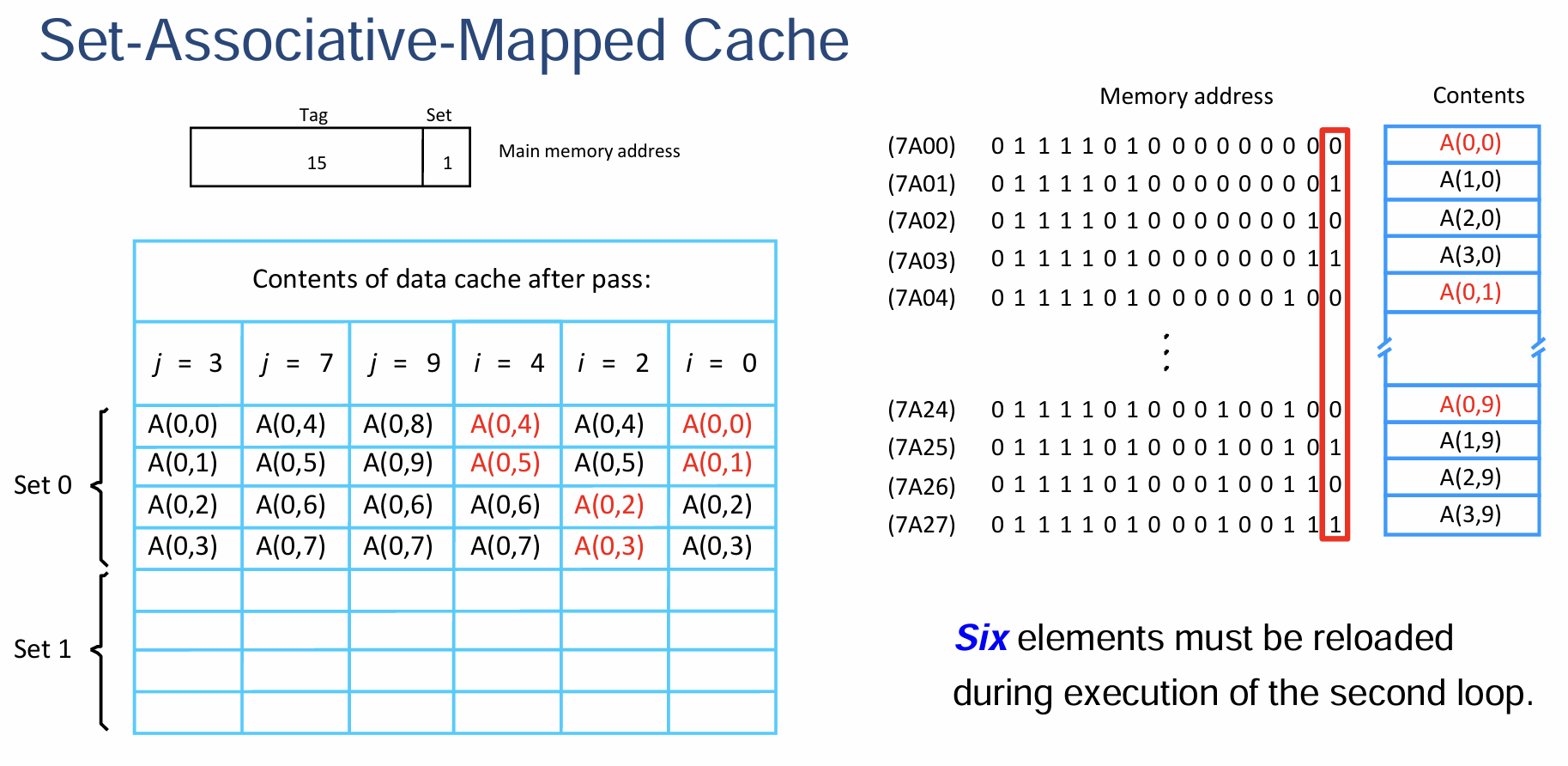
- 这道题有点乱七八糟的,我其实没太搞明白,还是上面的作业习题好理解一点
- 处理器的Cache被分为存储指令和数据的两部分,其中每个Data Cache存储容量为8个Block,每个Block仅存储一个字长为16位的字的数据
- 主存的Block是Word-Addressable的,地址的长度为16位
- 采取LRU算法作为当Cache满时从其中选取特定Line用于替换的替换算法

本文由作者按照 CC BY-NC-SA 4.0 进行授权