详解C++多线程编程基础
C++11引入了更完善的多线程支持,本文通过详尽注释的例程,简单介绍线程的创建与销毁方式、互斥锁的使用、条件变量的使用、线程池的概念等基础知识
详解C++多线程编程基础
一、C++11背景
- 随着单核处理器性能达到瓶颈,CPU厂商纷纷转向多核处理器设计以提升性能
- 为了适应多核的硬件结构,在C++11前实现多线程需借助操作系统提供的不同的API,如Linux的
<pthread.h>或Windows的<windows.h>,由于API接口差异存在差异,需要代码针对性地实现条件编译,并且构建和调试也很麻烦,这不利于软件的可移植性
- 为了适应多核的硬件结构,在C++11前实现多线程需借助操作系统提供的不同的API,如Linux的
- C++11引入如下五个头文件实现了语言级线程支持,所谓语言级指的是某种功能或特性是由编程语言本身(C++标准库)直接提供而非通过外部库或操作系统API实现的
<thread>:支持线程的创建、管理等基本操作<mutex>:实现互斥锁,保护共享数据免受并发访问冲突<atomic>:支持原子操作,确保无锁并发访问的线程安全性<condition_variable>:提供条件变量,实现线程间的同步与事件通知机制<future>:管理异步操作的结果,简化多线程任务的返回值传递与协调
二、关于线程
2.1 多进程与多线程
- 多进程并发:将应用程序划分为多个独立进程的同时,在每个进程中只使用一个线程
- 优点
- 由于操作系统对进程提供了大量的保护机制以避免进程间相互的数据误修改,故使用这种方法比直接使用多线程更容易写出安全的代码
- 缺点(由于多进程并发的缺点较为难办,故一般使用多线程并发)
- 进程间的通信往往十分复杂或速度较慢
- 操作系统管理这些进程所需的资源开销很大
- 优点
- 多线程并发:在同一个进程中执行多个线程(线程是轻量级的进程,每个线程可以独立的运行不同的指令序列,但是线程不独立的拥有资源,依赖于创建它的进程而存在)
- 优点
- 同一进程中的多个线程共享相同的地址空间,可以访问进程中的大部分数据,指针和引用可以在线程间进行传递,这使得同进程内的线程能方便地进行数据共享和通信
- 缺点
- 由于缺少操作系统提供的保护机制,这需要花费更多精力以保证对共享数据段的操作是以预想的操作顺序进行的,并需要极力避免死锁(Deadlock)
- 优点
- C++的多线程编程涉及在一个程序中创建和管理多个并发(有别于并行)执行的线程,使用相关功能需引入
<thread>标准库 - 一个进程中的多个线程的运行方式如下,子线程之于主线程类似Git的主分支之于其他分支,后续会讲到线程销毁方式有
join()和detach()两种方式,其中子线程join()相当于Git的merge入主分支,其伴随主线程的销毁而销毁,而detach()相当于不merge而自生自灭
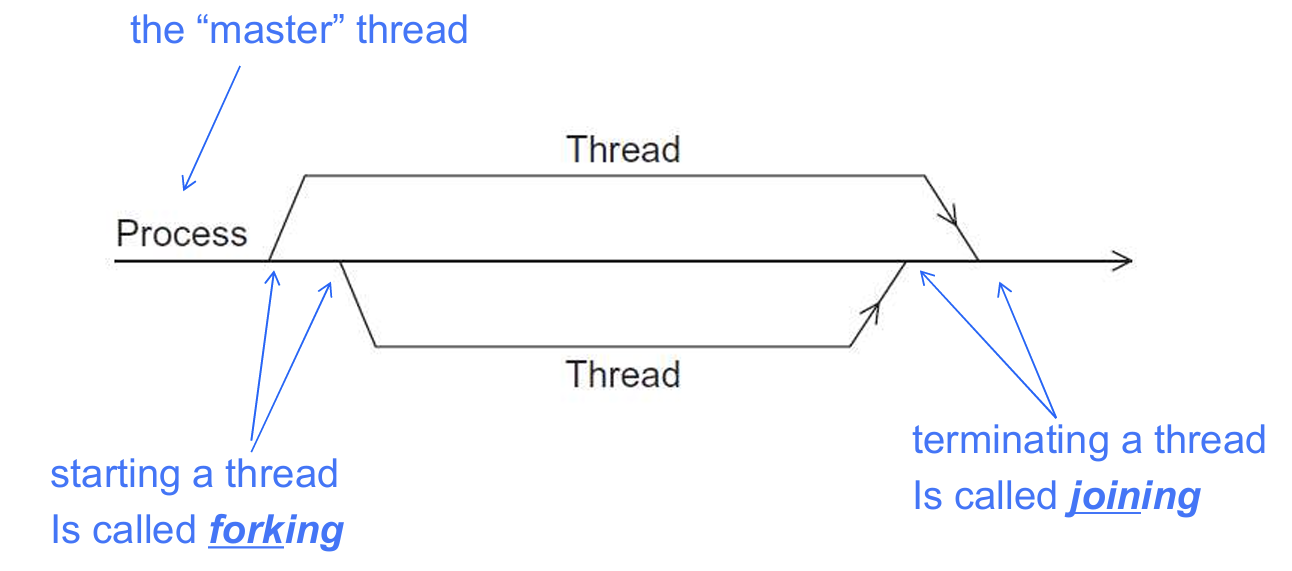
2.2 线程的创建执行
2.2.1 通过函数指针创建
- 把函数指针添加到线程当中即可创建线程,同一函数可被复用创建多个线程
- 线程
std::thread对象一旦被创建,立刻开始执行,而非等join()或detach()后才开始
1
2
3
4
5
6
7
#include <thread>
//函数形式为void Func()
std::thread myThread(Func);
//函数形式为void Func(int)
std::thread myThread(Func, 100);
2.2.2 通过Lambda表达式创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <iostream>
#include <thread>
int main()
{
//构造匿名函数并对其传参5以创建线程
std::thread _t(
[](int _count)
{
for (int _i = 0; _i < _count; _i++)
std::cout << "KON";
}, 5);
//开启线程进行测试
_t.join();
}
//KONKONKONKONKON
2.2.3 通过函数对象创建
- 通过重载了运算符
()的类对象(即可被当作函数使用的仿函数)也可以创建线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
#include <thread>
class PrintTask
{
public:
//重载运算符
void operator()(int _count) const
{
for (int _i = 0; _i < _count; _i++)
std::cout << "KON";
}
};
int main()
{
//PrintTask()创建了一个临时的PrintTask类对象,该对象可作为函数使用
std::thread _t(PrintTask(), 5);
_t.join();
}
//KONKONKONKONKON
2.2.4 创建分离匿名线程
- 先创建临时的匿名线程,然后用
detach()使其与主线程分离可创建分离线程(若不分离,匿名线程会直接被销毁,这会导致程序崩溃,因为线程必须被以join()或detach()指定销毁方式,详见后文二者的使用方法)- 分离线程在后台独立运行,执行完毕自动释放资源
- 主线程不再管理该线程的生命周期,若主线程退出,所有分离线程会被强制终止(这可能导致资源泄漏,故而需要在使用时注意内存的管理)
1
2
//函数形式为void thread_fun(int x)
std::thread(thread_fun, 100).detach();
2.3 线程函数的传参
- 值传递:直接传入参数
1
2
//传入函数指针和值参数列表
std::thread _t(Func, _arg1, _arg2);
- 引用传递:
- 若函数签名中需接收普通
&形式的参数,需要使用std::ref()而不是直接传入参数(由于线程构造函数会将参数拷贝到线程的内部存储中,无法达成传入引用的效果) - 若函数签名中需接收
const&形式的参数,需要使用std::cref()进行传参
- 若函数签名中需接收普通
- 指针传递:正常使用取址符
&传入即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
#include <thread>
void Func01(int& _x)
{
_x += 5;
}
void Func02(int* _x)
{
*_x += 5;
}
int main()
{
int _num1 = 0;
std::cout << "_num1=" << _num1 << "\n";
int _num2 = 0;
std::cout << "_num2=" << _num2 << "\n";
//函数指针接收引用,使用std::ref()传递引用
std::thread _t1(Func01, std::ref(_num1));
//函数指针接收指针,使用&传递指针
std::thread _t2(Func02, &_num2);
_t1.join();
std::cout << "_num1=" << _num1 << "\n";
_t2.join();
std::cout << "_num2=" << _num2 << "\n";
}
// _num1=0
// _num2=0
// _num1=5
// _num2=5
2.4 指定线程销毁方式
2.4.1 join()与detach()
- 线程对象一旦被创建就会立刻开始执行(而不是等指定销毁方式后才开始执行,指定销毁方式只是用来控制主线程是否等待线程执行完毕,或者让线程在后台独立运行),当线程启动后若不调用
join()或detach()而直接销毁线程对象会导致崩溃,所以必须选取两种方式中的一种来指定线程对象的销毁方式join():非匿名线程通过该方法阻塞主线程,主线程等待该线程执行完成后才会继续执行detach():使得新线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束
- 以下是
join()的使用例程,结果就是无限输出"Func01"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <iostream>
#include <thread>
void Func01()
{
while(1)
{
std::cout << "Func01\n";
}
}
void Func02(int _x)
{
std::cout << "Func02\n";
std::cout << _x << "\n";
}
int main()
{
//创建线程
std::thread _thread01(Func01);
std::thread _thread02(Func02, 100);
//阻塞在第一个线程的无限循环内
_thread01.join();
_thread02.join();
}
- 以下是
detach()的使用例程,结果就是无限交错输出"Func"和"Main Thread"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <iostream>
#include <thread>
void Func01()
{
while(1)
{
std::cout << "Func\n";
}
}
int main()
{
//创建线程
std::thread _thread(Func01);
//分离线程使其独立运行于后台
_thread.detach();
while(1)
{
std::cout << "Main Thread\n";
}
}
2.4.2 纠正一个错误认知
- 以下是一个综合两种销毁方式使用的例程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
#include <iostream>
#include <thread>
void Func01()
{
for (int _i = 0; _i < 5; _i++)
std::cout << "1\n";
}
void Func02()
{
for (int _i = 0; _i < 5; _i++)
std::cout << "2\n";
}
void Func03()
{
std::cout << "3\n";
}
int main()
{
//主线程已经启动
std::cout << "Main Thread Start\n";
//创建两个线程
//注意:线程即刻开始执行
std::thread _thread01(Func01);
std::thread _thread02(Func02);
//主线程阻塞,主线程需等待_thread01完成后才会输出"Flag"
//注意:此时_thread01和_thread02都处于运行状态
_thread01.join();
//注意:此时_thread01已经结束(这导致"Flag"一定在所有输出的"1"之后),而_thread02已经运行了一段时间,其可能已经结束也可能仍处于运行状态(这导致"Flag"并不一定在所有输出的"2"之前)
std::cout << "Flag\n";
_thread02.join();
//创建并分离匿名线程,然后主线程继续执行
std::thread(Func03).detach();
//主线程继续执行,不会等待分离线程执行
std::cout << "Main Thread Over\n";
//主线程结束后,分离的线程强行结束
}
//Main Thread Start
//1
//2
//1
//1
//2
//2
//1
//1
//2
//2
//Flag
//Main Thread Over
//3
- 我最初学习到这时存在一个认识误区,即错误地认为:
线程在调用了,实际上线程一旦被创建就开始了执行,实际上join()或detach()后才会开始执行,对于上述代码,主线程等待_thread01执行完后才会继而执行_thread02- 两个线程创建后是并发执行的,这本就是多线程提升运行效率的意义所在
- 虽然
join()方法会阻塞主线程使其等待子线程执行完后再继续执行,但子线程相互之间并不会相互阻塞,而是并发执行Func01和Func02使得输出的"1"和"2"交错
- 上述程序的输出结果使得当时的我疑惑,为何输出的
"Flag"处于所有的"1"和"2"之后呢- 实际上这是由于线程执行时间过短导致的偶然假象,我们能确定的只有
"Flag"必然在所有"1"之后被输出,且"Main Thread Over"必然在所有的"2"之后被输出,而"Flag"并不一定会在所有"2"后输出 - 如果我们将
Func01和Func02的输出循环都加长为10的话,那么就会发现"Flag"的输出并非一定在所有"2"之后,但一定在所有"1"之后
- 实际上这是由于线程执行时间过短导致的偶然假象,我们能确定的只有
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//Main Thread Start
//1
//1
//1
//1
//1
//2
//2
//2
//1
//2
//2
//1
//1
//1
//1
//2
//2
//Flag
//2
//2
//2
//Main Thread Over
//3
2.5 this_thread
this_thread是一个命名空间,提供了与当前线程相关的操作this_thread::get_id():获取当前线程的唯一标识符this_thread::yield():放弃当前线程执行,允许其他线程运行this_thread::sleep_for(std::chrono::seconds(2)):让当前线程休眠指定的时间this_thread::sleep_until():让当前线程休眠直到指定的时间点
- 参考如下例程(虽然此处暂未体现
yield()函数的效用)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
#include <thread>
#include <chrono>
void Func01()
{
std::cout << "Func01 Thread ID = " << std::this_thread::get_id() << "\n";
//退让当前线程放弃CPU时间片,允许其他线程运行
std::cout << "Thread yielding...\n";
std::this_thread::yield();
//休眠2秒
std::cout << "Thread sleeping for 2 seconds...\n";
std::this_thread::sleep_for(std::chrono::seconds(2));
//休眠到指定时间点
auto _now = std::chrono::system_clock::now();
auto _wakeTime = _now + std::chrono::seconds(3);
std::cout << "Thread sleeping until 3 seconds from now..." << std::endl;
std::this_thread::sleep_until(_wakeTime);
std::cout << "Func01 Thread finished" << std::endl;
}
int main()
{
std::thread _t01(Func01);
_t01.join();
}
//Func01 Thread ID = 0xbc
//Thread yielding...
//Thread sleeping for 2 seconds...
//Thread sleeping until 3 seconds from now...
//Func01 Thread finished
三、互斥锁
3.1 互斥锁的种类
- 互斥锁(Mutex)用于防止多个线程同时访问共享资源(需引入
<mutex>头文件)std::mutex是最基本的互斥锁,不可递归(即同一线程重复加锁会导致死锁)std::recursive_mutex是递归的互斥锁(允许同一线程多次加锁)std::time_mutex是定时的互斥锁(允许在指定时间内尝试加锁)std::recursive_timed_mutex是可递归且带超时功能的互斥锁
3.2 互斥锁的使用
- 当一个线程需要访问共享资源时,它首先需要锁定互斥锁,如果互斥量已经被其他线程锁定,那么请求锁定的线程将被阻塞,直到互斥锁被解锁
lock():上锁,若锁已被其他线程持有,则当前线程阻塞unlock():解锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <iostream>
#include <thread>
#include <mutex>
//全局互斥量
std::mutex mtx;
void PrintFunc(int _n, char _c)
{
//请求上锁
mtx.lock();
//访问或修改共享资源的某些操作
//一个随便写的东西
for (int _i = 0; _i < _n; _i++)
std::cout << _c;
std::cout << '\n';
//解锁
mtx.unlock();
}
int main()
{
std::thread _th1 (PrintFunc, 10, '*');//线程1:打印*
std::thread _th2 (PrintFunc, 20, '$');//线程2:打印$
_th1.join();
_th2.join();
}
//**********
//$$$$$$$$$$$$$$$$$$$$
- 如果使用了不同的互斥锁变量,因不涉及到同一锁的竞争,所以如下例程运行可能会出现交替打印的情况,因为两个线程都修改了共享的同一全局变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
#include <iostream>
#include <thread>
#include <mutex>
//两个全局互斥锁
std::mutex mtx1;
std::mutex mtx2;
int testNum = 0;
void PrintFunc1(int _n)
{
mtx1.lock();
//修改了共享的全局变量
for (int _i = 0; _i < _n; _i++)
{
testNum = 1;
std::cout << testNum << "\n";
}
mtx1.unlock();
}
void PrintFunc2(int _n)
{
mtx2.lock();
//修改了共享的全局变量
for (int _i = 0; _i < _n; _i++)
{
testNum = 2;
std::cout << testNum << "\n";
}
mtx2.unlock();
}
int main ()
{
std::thread _th1 (PrintFunc1, 5);
std::thread _th2 (PrintFunc2, 5);
_th1.join();
_th2.join();
}
//每次运行的输出结果有所差异
//12
//2
//
//12
//
//12
//
//12
//
//1
3.3 lock_guard
- 创建
lock_guard对象时,它将尝试获取提供给它的互斥锁的所有权,当控制流离开lock_guard对象的作用域时,lock_guard析构并释放互斥量,其具有以下性质- 创建时自动使互斥锁上锁
- 无需手动解锁,但不能中途解锁,必须等作用域结束才会自动析构并解锁
- 不能复制(即不能通过
=复制或者通过拷贝构造创建新的实例,因为若能复制则会导致多个lock_guard管理同一个互斥锁,它们的作用域结束时会导致重复解锁,这是未定义的)
- 如下例程仅输出两行后便被阻滞了,并没有继续输出,这是因为第一个
SafeIncrement()内递归创建的子线程由于互斥锁已在主线程被上锁而导致需要等待解锁,而主线程又需要等待子线程执行完毕才能继续执行从而解锁,这就导致了死锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
#include <thread>
#include <mutex>
//全局变量
int v = 0;
//用于保护全局共享变量b
std::mutex vMutex;
void SafeIncrement()
{
//创建lock_guard自动尝试加锁
const std::lock_guard<std::mutex> lock(vMutex);
//递增全局变量
v++;
//输出当前
std::cout << "main id = " << std::this_thread::get_id() << std::endl;
std::cout << "main v = " << v << '\n';
//尝试使用当前函数创建新的递归线程并执行,当前线程会被阻塞等待它们执行完成后才继续
std::thread _t(SafeIncrement);
_t.join();
//检测新的线程是否成功执行,使得主线程继续执行到此
std::cout << "main v = " << v << '\n';
}
int main()
{
std::thread _t(SafeIncrement);
_t.join();
}
//main id = 0x60
//main v = 1
3.4 unique_lock
unique_lock是lock_guard的加强版,它具有后者所有功能的同时还拥有新的功能,能应对更复杂的锁定需要,其具有以下特点- 创建时可选择不立刻上锁(指定第二参数为
std::defer_lock)而在需要时再锁定 - 可以随时加锁与解锁,析构时自动释解锁(同
lock_grard) - 不可复制,可移动(可以通过移动赋值运算符
lock2 = std::move(lock1)或移动构造函数lock3(std::move(lock2))转移锁的控制权,原先的锁会失效变为空锁,防止重复解锁) - 条件变量需要该类型的锁作为参数(此时必须使用
unique_lock)
- 创建时可选择不立刻上锁(指定第二参数为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
#include <iostream>
#include <thread>
#include <mutex>
struct Account
{
//防止隐式转换的构造函数,确保只能被显式调用
explicit Account(int num) : money{ num } {}
//账户金额(局部而非全局的变量)
int money;
//为账户金额上锁(局部而非全局的锁)
std::mutex moneyMutex;
//虽然金额和锁都是局部的,但若多个转账操作访问同一个账户的引用
//那么这个账户的成员对于多个操作来说也是共享的,所以要使用互斥锁进行保护
};
//从一个结构体中的变量减去一个数字,然后加到另一个结构体的变量中去,即转账操作
void Transfer(Account& _from, Account& _to, int _num)
{
//std::defer_lock使得创建时不自动加锁
std::unique_lock<std::mutex> _lock1(_from.moneyMutex, std::defer_lock);
std::unique_lock<std::mutex> _lock2(_to.moneyMutex, std::defer_lock);
//此处std::lock将两个锁一起加锁,函数内部算法(如按内存地址排序)强制所有线程以一致的顺序获取锁,避免加锁顺序不同导致的死锁
//若不使用std::lock同时上锁,可能出现线程1先对_from上锁,然后线程2紧接着对线程1中对应的_to引用上锁而导致两个线程互相等待形成死锁
std::lock(_lock1, _lock2);
//进行实际的转账操作
_from.money -= _num;
_to.money += _num;
//作用域结束自动解锁,也可以使用.unlock()手动解锁
}
int main()
{
//创建两个有初始金额的账户
Account _acc1(100);
Account _acc2(50);
std::cout << "_acc1 money before = " << _acc1.money << std::endl;
std::cout << "_acc2 money before = " << _acc2.money << std::endl;
//创建两个线程,分别执行从账户1向账户2转账10、从账户2向账户1转账5的任务
//注意引用传参需要以std::ref()包裹
std::thread _t1(Transfer, std::ref(_acc1), std::ref(_acc2), 10);
std::thread _t2(Transfer, std::ref(_acc2), std::ref(_acc1), 5);
_t1.join();
_t2.join();
//输出检测需要在所有join后进行,否则输出的结果不一定是最终算出来的结果
std::cout << "_acc1 money after = " << _acc1.money << std::endl;
std::cout << "_acc2 money after = " << _acc2.money << std::endl;
}
//_acc1 money before = 100
//_acc2 money before = 50
//_acc1 money after = 95
//_acc2 money after = 55
- 虽然所有
lock_guard能做到的事都可用unique_lock做到而反之不然,看似前者已无用,但需要使用锁的时候我们仍需首先考虑用lock_guard,因为它是最简单的锁
四、条件变量
4.1 关于条件变量
- 头文件
<condition_variable>中的条件变量与互斥锁一起使用以实现线程间的同步,主要有以下两种条件变量,后文未特殊说明则默认以condition_variable为例condition_variable:必须结合unique_lock使用condition_variable_any:可以使用任何的锁
- 条件变量允许一个或多个线程等待通知后,再检测某条件是否满足,以决定是否停止等待,例如在某线程中调用公共条件变量对象的以下成员方法,便可阻塞该线程使其进行等待
wait(...):等待直到通知后检测谓词决定是否解锁wait_for(...):等待直到通知后检测是否解锁,或在一定时间后停止等待wait_until(...):等待直到通知后检测是否解锁,或在确定时间点处停止等待
- 若想解除线程的等待,那就需要先调用同一公共条件变量对象的以下成员方法进行通知
notify_one():通知仅一个调用了同一个条件变量的等待函数导致陷入等待的线程(具体唤醒哪个线程取决于实现,通常是等待时间最长的线程)notify_all():通知所有的调用了同一个条件变量的等待函数导致陷入等待的线程
- 被通知到的线程就会继而对布尔条件谓词进行检查,若其为
true则解除等待,false则继续陷入等待阻塞状态(若被notify_one()唤醒的线程因条件谓词未满足而重新进入等待,函数并不会再次尝试通知其他等待线程)
4.2 wait(...)的使用
- 如下是
wait()函数的签名,模板参数Predicate即谓词,是返回bool类型的可调用对象(通常是Lambda表达式或函数)而非单纯一个bool类型值
1
2
3
4
5
template <class Predicate>
void wait(
std::unique_lock<std::mutex>&,
Predicate
);
- 当某个线程调用了某个共享的条件变量的
wait()时- 当前线程会被阻塞,直到另外某线程调用同一条件变量的通知函数唤醒当前线程
- 同时会释放当前线程已上锁的互斥锁,以允许其他线程操作共享数据,避免死锁
- 以下是一个较为简单的例程,展示了条件变量的
wait(...)和notify_one()的用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
#include <iostream>
#include <vector>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void WorkThread()
{
//先上锁
std::unique_lock<std::mutex> _lock(mtx);
std::cout << "WorkThread Starts\n";
//当被通知后,若满足谓词条件则继续执行工作,否则又陷入等待状态
cv.wait(_lock,
[]()
{
return ready;
}
);
//工作线程执行完毕
std::cout << "WorkThread Ends\n";
}
int main()
{
std::cout << "MainThread Starts\n";
//创建并执行工作线程
std::thread _workThread(WorkThread);
//工作线程理应被cv.wait(...)阻塞,其会交还锁权限,程序继续向下执行主线程,直到主线程通知它
//不能在此处立刻join,这会死锁,因为join后主线程必须等待工作线程结束,而工作线程仍在wait
//_workThread.join();
//模拟经过一些操作后使得ready谓词为true
{
std::lock_guard<std::mutex> _lock(mtx);
ready = true;
}
//通知正在等待的工作线程
cv.notify_one();
//指定结束方式,等待工作线程结束
_workThread.join();
std::cout << "MainThread Ends\n";
}
//MainThread Starts
//WorkThread Starts
//WorkThread Ends
//MainThread Ends
- 以下是一个更为复杂的例程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
//共享数据容器
struct SharedData
{
std::vector<std::string> msgs; //记录生产和消费的信息队列(直接cout是非线程安全的,会导致交错打印)
std::queue<int> data; //存放生产出的数据队列(消费时从队首取数据)
std::mutex mtx; //保护共享数据的互斥锁
std::condition_variable cv; //协调生产消费的条件变量
};
//生产者,生成若干个数据后结束
void Producer(SharedData& _sd, int _num, int _id)
{
for (int _i = 0; _i < _num; _i++)
{
//每次对传入的SharedData操作时先上锁
std::lock_guard<std::mutex> _lock(_sd.mtx);
//生产数据,即向传入的SharedData的队列塞数据
_sd.data.push(_i);
_sd.msgs.emplace_back("P" + std::to_string(_id) + " Produces " + std::to_string(_i));
//每次生产一个数据后唤醒仅一个等待的消费者
_sd.cv.notify_one();
} //_lock自动解锁
//先上锁
std::lock_guard<std::mutex> _lock(_sd.mtx);
_sd.msgs.emplace_back("P" + std::to_string(_id) + " Quits");
} //_lock自动解锁
//消费者,持续消费直到队列空且生产完成
void Consumer(SharedData& _sd, int _id)
{
//不断循环,直到将传入的SharedData对象的队列中的数据消费殆尽
while (true)
{
//先上锁,condition_variable必须接收unique_lock类型的锁
std::unique_lock<std::mutex> _lock(_sd.mtx);
//使用wait阻塞自身,直到被生产者通知后检测谓词
_sd.cv.wait(_lock,
[&]()
{
//若存在数据可消费,则执行后续消费操作,否则继续等待
return !_sd.data.empty();
}
);
//消费数据
_sd.msgs.emplace_back("C" + std::to_string(_id) + " Consumes " + std::to_string(_sd.data.front()));
_sd.data.pop();
std::this_thread::sleep_for(std::chrono::milliseconds(200));
//若数据队列已空,则终止消费循环
if (_sd.data.empty())
{
_sd.msgs.emplace_back("C" + std::to_string(_id) + " Quits");
return;
}
} //_lock自动解锁
}
int main()
{
//创建共享数据
SharedData _sd;
std::thread _p1(Producer, std::ref(_sd), 3, 0); //生产3个数据,编号为0
std::thread _p2(Producer, std::ref(_sd), 4, 1); //生产4个数据,编号为1
std::thread _p3(Producer, std::ref(_sd), 5, 2); //生产5个数据,编号为2
std::thread _c1(Consumer, std::ref(_sd), 0);
std::thread _c2(Consumer, std::ref(_sd), 1);
std::thread _c3(Consumer, std::ref(_sd), 2);
_p1.join();
_p2.join();
_p3.join();
_c1.join();
_c2.join();
_c3.join();
//取出记录了生产消费情况的消息,并检查是否存在剩余数据
for (auto _msg : _sd.msgs)
std::cout << _msg << "\n";
std::cout << "Data Left " << _sd.data.size();
}
//P0 Produces 0
//P0 Produces 1
//P0 Produces 2
//P0 Quits
//C0 Consumes 0
//C0 Consumes 1
//C0 Consumes 2
//C0 Quits
//P1 Produces 0
//P1 Produces 1
//P1 Produces 2
//P1 Produces 3
//P1 Quits
//P2 Produces 0
//C1 Consumes 0
//C1 Consumes 1
//P2 Produces 1
//C1 Consumes 2
//C1 Consumes 3
//C1 Consumes 0
//C1 Consumes 1
//C1 Quits
//P2 Produces 2
//P2 Produces 3
//P2 Produces 4
//P2 Quits
//C2 Consumes 2
//C2 Consumes 3
//C2 Consumes 4
//C2 Quits
//Data Left 0
4.3 wait_for(...)的使用
4.3.1 无谓词
wait_for(...)的签名有两个重载,以下是无谓词版本,其中std::chrono::duration<Rep, Period>是C++标准库中用于表示时间间隔的模板类,例如std::chrono::duration<int64_t, std::ratio<1>>即std::chrono::seconds表示秒
1
2
3
4
5
6
template <class Rep, class Period>
//传入互斥锁、等待时间长度
std::cv_status condition_variable::wait_for(
unique_lock<mutex>&,
const chrono::duration<Rep,Period>&
);
- 其中返回值类型
std::cv_status是一个枚举类
1
2
3
4
5
enum class cv_status
{
no_timeout, //等待成功(条件变量被通知)
timeout //等待超时(在等待时间内未被通知)
};
- 当在线程内调用条件变量的
wait_for时,该线程会阻塞并等待通知- 若在指定时间内被通知,函数返回
std::cv_status::no_timeout,线程会被唤醒而无需检测谓词,即线程会重新获取锁然后继续执行 - 若超过指定时间仍未被通知,函数返回
std::cv_status::timeout,线程仍会因为超时而被唤醒,同样无需检测谓词而继续执行,但仍可对这种情况进行特殊处理(比如重试)
- 若在指定时间内被通知,函数返回
- 值得注意的是,在某些平台上
wait_for的精确度可能受时钟精度影响,超时不一定完全精确
4.3.2 带谓词
- 带谓词的版本如下,
Predicate通常是一个可调用对象,如Lambda表达式或函数
1
2
3
4
5
6
template <class Rep, class Period, class Predicate>
bool wait_for (
unique_lock<mutex>&,
const chrono::duration<Rep,Period>&,
Predicate
);
- 该函数与不带谓词版本的返回不同,我们分情况讨论其工作方式(无论如何,当
wait_for函数超时或返回true后,线程都会继续执行后续代码)- 若该线程调用的条件变量在等待时间内未被通知,那么在函数超时后,若谓词:
- 返回
true,则wait_for返回true,线程重新获得锁并继续执行后续代码 - 返回
false,则wait_for返回false,线程仍然会继续执行后续代码,但我们可以选择通过if等语句特殊处理这种情况
- 返回
- 若在等待时间内被通知,若谓词:
- 返回
true,则wait_for返回true,线程继续执行后续代码 - 返回
false,则wait_for继续等待直至超时,超时后套用前面的处理方式
- 返回
- 若该线程调用的条件变量在等待时间内未被通知,那么在函数超时后,若谓词:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void Work()
{
std::unique_lock<std::mutex> _lock(mtx);
//线程会阻塞在wait_for返回结果前,一旦其由于被通知或超时而产生返回值,线程就会继续执行,针对两种返回结果进行不同的处理
if (cv.wait_for(_lock, std::chrono::seconds(3), [] { return ready; }))
std::cout << "Ready!\n";
else
std::cout << "Timeout and Not Ready!\n";
}
int main()
{
//先维持ready为false,测试超时
std::thread _td1(Work);
_td1.join();
//继续维持ready为false,测试通知
std::thread _td2(Work);
cv.notify_all();
_td2.join();
//然后改变ready为true,测试超时
std::thread _td3(Work);
//用于修改共享对象的作用域,便于自动解锁
{
std::unique_lock<std::mutex> _lock(mtx);
ready = true;
}
_td3.join();
//然后改回false再改回true后,测试通知
std::thread _td4(Work);
{
std::unique_lock<std::mutex> _lock(mtx);
ready = true;
cv.notify_all();
}
_td4.join();
}
//第一行输出:现实世界实际等待了3秒
//第二行输出:现实世界实际等待了3秒
//第三、四行输出:紧跟着第二行立刻出现
//Timeout and Not Ready!
//Timeout and Not Ready!
//Ready!
//Ready!
五、线程池
5.1 线程池的概念
- 多次创建并销毁线程会消耗内存,影响程序整体性能,创建过多的线程有以下缺点
- 有些线程未被充分使用就被销毁,导致资源浪费
- 销毁和创建线程太耗费时间,导致其它线程饥饿
- 对于需要较多使用线程的程序,可以使用线程池来一定程度上减缓程序运行时创建与销毁线程的代价,即在程序开始运行前创建多个线程(池化),程序运行时从线程池中抓取线程使用即可
5.2 线程池的实现
- 线程池类的核心就是下面两个东西,以下提供一个较为基础的实现
- 工作线程:线程池中的具体线程
- 任务队列:用于存放没有处理的任务,提供一种缓冲机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
#ifndef _THREAD_POOL_HPP_
#define _THREAD_POOL_HPP_
#include <iostream>
#include <stdexcept>
#include <vector>
#include <queue>
#include <assert.h>
#include <thread>
#include <condition_variable>
//限制的最大线程数目
const int MAX_THREADS = 1000;
//模板类,T是任务类型
template <typename T>
class ThreadPool
{
private:
std::vector<std::thread> workThreads; //工作线程
std::condition_variable cv; //条件变量
std::queue<T*> tasksQueue; //待完成的任务队列
std::mutex tasksMutex; //保护任务队列的互斥锁
bool stop = false; //控制线程是否停止
public:
ThreadPool(int); //按数量初始化线程
~ThreadPool(); //销毁所有线程
void Append(T*); //向任务队列中追加新的任务指针
private:
void RunThread(); //线程函数,运行处理任务
};
template <typename T>
ThreadPool<T>::ThreadPool(int _number)
{
//排除非法数量
if (_number <= 0 || _number > MAX_THREADS)
throw std::exception();
//初始化线程并存入列表
for (int _i = 0; _i < _number; _i++)
{
//通过Lambda初始化线程(除了Lambda,还可构造一个静态成员函数并显式传递this以初始化线程)
workThreads.emplace_back(
//仅捕获this指针
[this]()
{
//成员函数不能直接作为线程函数初始化线程,因为其有一个隐式的this参数
this->RunThread();
}
);
std::cout << "Initialize Thread " << _i << "\n";
}
}
template <typename T>
ThreadPool<T>::~ThreadPool()
{
//对任务队列上锁
std::lock_guard<std::mutex> _lock(tasksMutex);
//线程内是无限循环,若不使用stop使其暂停,线程不会随着线程池析构而结束循环
stop = true;
//通知所有线程
cv.notify_all();
//在析构函数中指定线程销毁方法为join
for (auto& _thread : workThreads)
_thread.join();
}
template <typename T>
void ThreadPool<T>::Append(T* _request)
{
//上锁然后附加新任务到任务队列
std::lock_guard<std::mutex> _lock(tasksMutex);
tasksQueue.push(_request);
//添加新任务后,通知一个正在等待任务的线程
cv.notify_one();
}
template <typename T>
void ThreadPool<T>::RunThread()
{
//无限调用线程执行任务
while (true)
{
//上锁
std::unique_lock<std::mutex> _lock(tasksMutex);
//如果stop为true且任务队列为空,退出循环
if (stop && tasksQueue.empty())
break;
//若任务为空则等待通知,有任务时才启动线程
cv.wait(_lock,
[&]
{
return !this->tasksQueue.empty();
}
);
//取出任务队列头部任务,然后实际开始执行任务
T* _request = tasksQueue.front();
tasksQueue.pop();
//本线程后续无需使用公共变量,故解锁以提升并发性
_lock.unlock();
//执行任务,假定所有任务类型都实现了Process函数
if (_request)
_request->Process();
//由于任务开辟在堆区,故销毁
delete _request;
}
std::cout << "Thread Quits\n";
}
#endif
- 以下是测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#include "ThreadPool.hpp"
#include<string>
#include<math.h>
class Task
{
public:
void Process()
{
//运行一些麻烦的运算
long _i = 100000;
while (_i != 0)
{
int _j = sqrt(_i);
_j = sqrt(_j);
_i--;
}
std::cout << "Finished\n";
}
};
int main(void)
{
//初始化拥有一定数量线程的线程池
ThreadPool<Task> _pool(5);
//跑一定数量的任务
for (int _i = 0; _i < 10; _i++)
{
//在任务池中销毁,或使用智能指针
Task* _t = new Task();
//添加任务给任务池
_pool.Append(_t);
}
//由于任务有限,所以创建完成任务后线程池会销毁而析构,导致任务未执行完,所以等一小会
std::this_thread::sleep_for(std::chrono::seconds(5));
}
六、线程局部存储
- 线程局部存储(Thread Local Storage, TLS)允许每个线程拥有自己的本地数据副本,这需通过关键字
thread_local修饰共享变量实现- 使用TLS能避免共享资源的争用,因为每个线程都有自己的副本
- 使用TLS能减少锁的使用,从而提高多线程程序的并发性能
- 例如使用TLS变量存储线程中需多次使用的计算结果,以避免重复计算
- 使用全局变量而非局部变量可以避免在每个线程内多次创建临时变量的性能消耗
- 由于每个线程的任务需求不同,计算结果对其他线程无意义,就无需交流给其他线程,所以不需对该变量写入(避免争夺该公共变量),故而此场景下没必要使用锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <iostream>
#include <thread>
thread_local int threadData = 0;
void threadFunction(int _edit)
{
//每个线程都有自己的threadData副本
threadData = _edit;
std::cout << threadData << "\n";
}
int main() {
std::thread t1(threadFunction, 6);
std::thread t2(threadFunction, 7);
t1.join();
t2.join();
}
//6
//7
本文由作者按照 CC BY-NC-SA 4.0 进行授权