浅析设计模式七大原则
在学习使用各种设计模式前,先要了解设计模式所遵循的设计原则,但不存在完美通用的架构,应当以工程实践为准则,而非死板遵循设计原则、设计模式,切忌过度设计
浅析设计模式七大原则
一、设计模式、设计原则、敏捷开发
1.1 设计模式
- 设计模式(Design Pattern)是软件开发过程中针对常见问题设计的通用解决方案
- 恰当的使用设计模式可以降低代码维护成本、提升代码复用性,使得项目更加规范且更易扩展
1.2 设计原则
- 设计原则(Design Principle)指的是抽象性比较高、编程都应该遵守的原则,对应的设计模式是解决具体场景下特定问题的套路,即设计模式要遵循设计原则
- 设计模式不一定能保证完美遵循所有设计原则,有时由于特定场景需求而会违反某些原则,我们也不应当死板僵硬地为了遵循某项原则而去忽略实际生产中的需求
1.3 敏捷开发
- 建议了解工程实践中的敏捷开发概念,并阅读“技术不重要,重要的是AA、BB以及CC”,切忌过度设计
二、开闭原则(OCP)
开闭原则是总纲,其它六个原则都是实现开闭原则的方法
2.1 定义
- 开闭原则(Open Closed Principle):软件中的实体(类,模块,函数等等)应该对扩展开放,对修改封闭,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为
2.2 背景与优点
- 开闭原则的主旨是为了拥抱变化,并且在变化过程中保持系统的可维护性和代码的重用性,遵循了开闭原则的代码,面对实际开发场景中需求的变化,应当尽可能地通过模块的扩展来满足,而尽量不修改该模块的源代码
- 此外,在产品化的环境中,改变源代码需要代码审查、单元测试,以及许多诸如此类的用以确保产品使用品质的过程,而遵循开闭原则的代码由于在扩展时并不发生改变,因此无需上述的过程
2.3 案例
- 请跳转至依赖倒置原则的案例处,开闭原则体现在我们设计
SkillManager类的时候就考虑到了其管理的技能将在未来有许多扩展,所以就提前设计了Skill这个抽象基类,将其指针作为成员变量作为接口,以后每有新技能就只需新写一个Skill的子类即可,若SkillManager想要使用这个新的类型的技能,只需要将接口指针指向这个技能类型的实例即可
2.4 注意事项
- 为了遵守开闭原则,在做系统设计(概要设计、详细设计)的时候就要考虑到未来的扩展和改变
- 要用抽象构建框架,用实现扩展细节,抽象要合理,要对需求的变更有前瞻性和预见性
三、单一职责原则(SRP)
类的职责要单一
3.1 定义
- 单一职责原则(Single Responsibility Principle):一个类只负责一项职责,即一个类应该只有一个发生变化的原因
3.2 背景与优点
- 如果一个类有多个职责,这些职责就耦合在了一起,会影响复用性,并且其中一个职责发生变化时可能会影响其它的职责
- 假设类A负责两个职责P1和P2,当由于职责P1需求发生改变而需要修改类A时,有可能会导致原本运行正常的职责P2功能发生故障;SRP的解决方案就是分别建立两个类 A1与A2,使A1完成职责P1,A2完成职责P2
- 遵循该原则有以下优点
- 降低类的复杂度,一个只负责一项职责的类的逻辑肯定要比多项职责简单
- 提高类的可读性,提高系统的可维护性
- 降低变更引起的风险
3.3 案例
- 我们想模拟程序员写C++代码,可以如下实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class Programmer
{
private:
std::string name;
public:
Programmer() :name("") {}
Programmer(std::string _name) :name(_name) {}
//Programmer写代码的函数
void Coding()
{
std::cout << name << " writes C++\n";
}
};
int main()
{
//实例化并调用方法
Programmer wz("WhythZ");
wz.Coding();
//WhythZ writes C++
}
- 如果想要扩展到写所有的语言,比如还想模拟写Java,这时候如果遵循SRP原则就应当分两个类来分别实现程序员写不同的语言的功能,如下所示
1
2
3
4
5
6
7
8
9
void CppProgrammer::Coding()
{
std::cout << name << " writes C++\n";
}
void JavaProgrammer::Coding()
{
std::cout << name << " writes Java\n";
}
- 对于更复杂的场景来说这样是没毛病的,对于逻辑简单的场景来说,我们可以违背SRP原则来减少修改的耗费(按照上面那样虽然遵循了SRP,但语言太多了,每次新增功能都要新写一个类),下面是一个修改的例子,此处是在代码级别上违背SRP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Programmer
{
private:
std::string name;
std::string lang;
public:
Programmer() :name(""), lang("") {}
Programmer(std::string _name, std::string _lang) :name(_name), lang(_lang) {}
//Programmer写代码的函数
void Coding()
{
std::cout << name << " writes " << lang << "\n";
}
};
int main()
{
//实例化并调用方法
Programmer wz_1("WhythZ", "C++");
wz_1.Coding();
//WhythZ writes C++
Programmer wz_2("WhythZ", "Java");
wz_2.Coding();
//WhythZ writes Java
}
- 上面这种修改方式仍有隐患,因为程序员写不同的代码所需要实现的东西并不一样,这里只是简化成了仅仅打印语言的名字,实际并没有那么简单,随着需求的语言种类的增加,每次修改都需要对这个
Coding函数进行更改,会带来对原有正常运行的功能的风险 - 所以我们还可用另一种方式对该代码进行修改,即增加新的方法,这也是违反了SRP原则的(此处是对SRP的方法级别的违背)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class Programmer
{
private:
std::string name;
public:
Programmer() :name("") {}
Programmer(std::string _name) :name(_name) {}
//Programmer写代码的函数
void CodingCpp()
{
std::cout << name << " writes C++\n";
}
void CodingJava()
{
std::cout << name << " writes Java\n";
}
};
int main()
{
//实例化并调用方法
Programmer wz("WhythZ");
wz.CodingCpp();
//WhythZ writes C++
wz.CodingJava();
//WhythZ writes Java
}
3.4 注意事项
- 根据实际情况的不同,在特定情境下(如上述案例所示),可以在代码级别(逻辑足够简单)或方法级别(方法足够少)上违反SRP原则,以减少风险
- 职责扩散(因为某种原因,职责P被分化为粒度更细的职责P1和P2)的存在使得我们需要在程序设计种不断有意识地重构代码来遵循SRP原则
四、里氏替换原则(LSP)
子类的方法重写不应破坏其作为基类的功能,即子类对象应当可以替代所有父类对象
4.1 定义
- 里氏替换原则(Liskov Substitution Principle):派生类(子类)对象可以在程序中代替其基类(超类)对象而不产生问题(但反之不成立,即基类对象无法代替子类对象)
- 子类必须完全实现父类的抽象方法,但最好不能覆盖父类的非抽象方法
- 子类可以实现自己特有的方法,以完成新增功能需求
- 当子类覆盖或实现父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松;方法的后置条件(即方法的返回值)要比父类更严格
- 只有当衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为
4.2 背景
- 类A完成了方法P1,现子类B需要将功能P1进行扩展,扩展后的功能为P,功能P由父类A的原功能P1与子类B的新功能P2组成,则子类B在完成新功能P2的同时(若不小心重写了P1方法),有可能会导致子类B想要调用继承自父类A的原有功能P1时发生故障,这就导致在项目代码中,子类B的对象无法代替父类A的对象
- 解决方法就是避免子类对父类方法的覆盖,一定要重写的话,子类就需要使得其同名方法在相同条件下和父类原方法得出来的输出结果一致
4.3 案例
- 类
Base中提供了P1方法实现两数相加,子类Child在此处未遵循LSP,重写了父类的方法P1用于实现子类的特性功能P,这就导致了子类Child的对象无法代替父类Base的对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class Base
{
public:
virtual int P1(int _num1, int _num2)
{
return _num1 + _num2;
}
};
class Child :public Base
{
public:
int P1(int _num1, int _num2)
{
return (_num1 + _num2) * 100;
}
int P2(int _num)
{
return _num + 50;
}
int P(int _num1, int _num2)
{
return P2(this->P1(_num1, _num2));
}
};
int main()
{
Base base;
Child child;
std::cout << "Base::P1(1,2)=" << base.P1(1, 2) << "\n";
//Base::P1(1,2)=3
std::cout << "Child::P1(1,2)=" << child.P1(1, 2) << "\n";
//Child::P1(1,2)=300
}
- 我们应当在不影响方法
P1的条件下进行功能P的实现
1
2
3
4
5
6
7
8
class Child :public Base
{
public:
int P(int _num1, int _num2)
{
return (_num1 + _num2) * 100 + 50;
}
};
五、依赖倒置原则(DIP)
高层模块要依赖于抽象接口而非具体的类;接口(Interface)是抽象类的一种特例(但二者并不等同,请勿混淆),接口中的所有方法都必须是抽象的
5.1 定义
- 依赖倒置原则(Dependence Inversion Principle):指面向接口编程依赖于抽象而不依赖于具体,即写代码时用到具体类时,不与具体类交互,而与具体类的上层接口交互
- 高层模块、低层模块、细节都应该依赖抽象
- 高层模块不应该依赖低层模块
- 抽象不应该依赖细节
- 因为抽象是稳定的,而细节是多变的,在高层模块中使用抽象能避免频繁修改产生的风险
5.2 案例
- 下面这个对技能管理器(高层模块)以及技能(抽象)与其子技能(底层模块,其提供的方法就是细节)三个方面的实现就是遵循依赖倒置原则的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
#include <iostream>
class Skill
{
public:
virtual void Use() = 0;
//声明虚析构函数,防止警告
virtual ~Skill() {}
};
class FireSkill :public Skill
{
public:
void Use()
{
std::cout << "Fire!";
}
};
class IceSkill :public Skill
{
public:
void Use()
{
std::cout << "Ice!";
}
};
class ThunderSkill :public Skill
{
public:
void Use()
{
std::cout << "Thunder!";
}
};
class SkillManager
{
public:
//Skill基类指针用于指向其子类示例,其只关心该对象是Skill(抽象),而不关心具体是什么技能(细节)
Skill* skill;
SkillManager(Skill* _skill) :skill(_skill) {}
void UseSkill()
{
skill->Use();
}
};
int main()
{
FireSkill* fireSkill = new FireSkill();
SkillManager manager(fireSkill);
manager.UseSkill();
//Fire!
delete fireSkill;
}
- 注意到我们在高层模块
SkillManager中使用了抽象基类Skill的指针(这个就是接口)作为成员,而不是直接使用某个子技能的对象作为成员,这样我们在实例化的时候就可以通过更改SkillManager::skill指针的指向的方式来更改技能 - 如果不这样做的话,比如在
SkillManager中使用FireSkill skill;作为成员,那么我们如果想更改SkillManager管理的技能的类型,就必须要更改该成员为例如IceSkill skill;,这样更改高层模块的代码是高风险的
5.3 反思
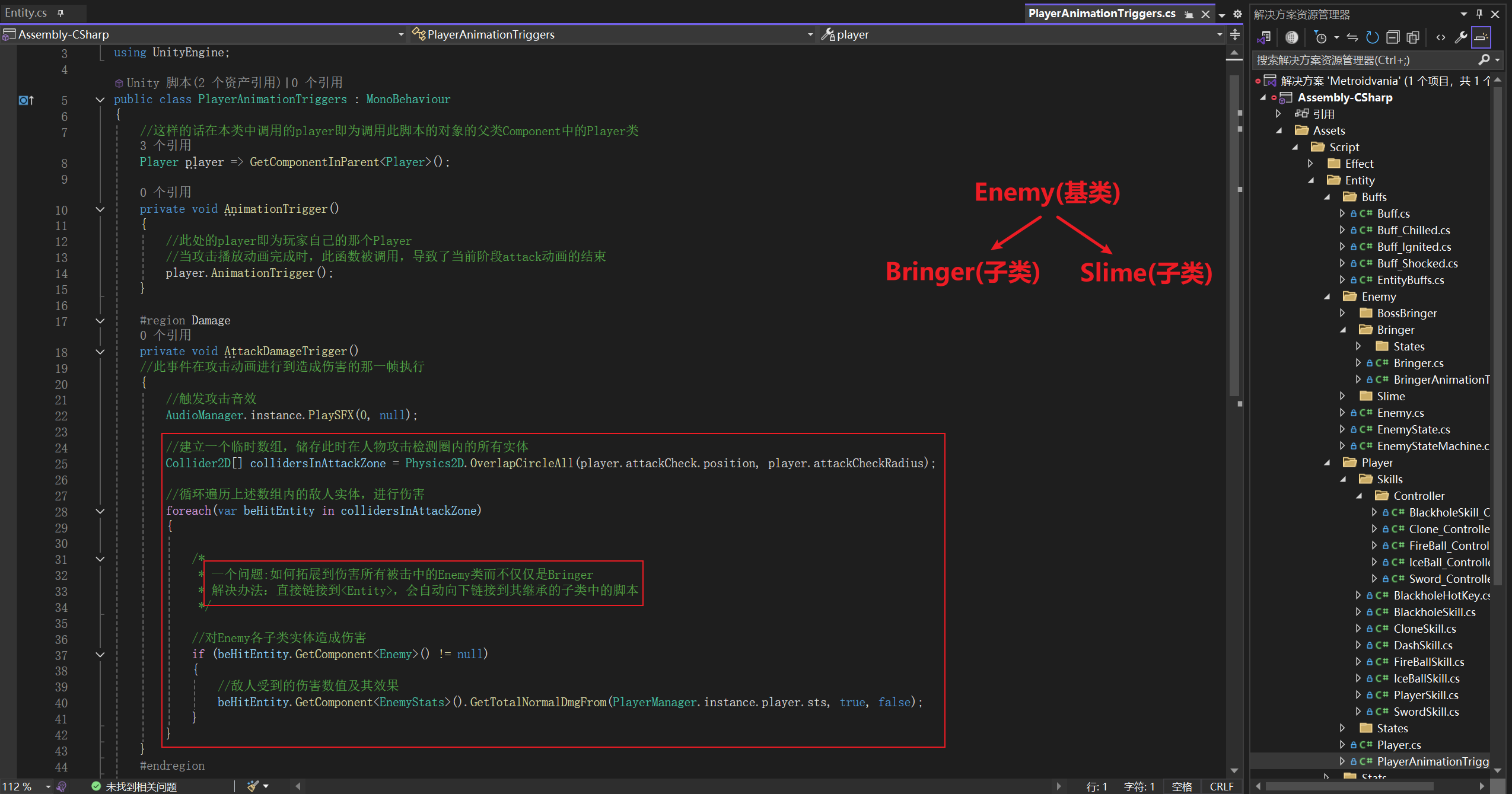
- 在学习了依赖倒置原则之后,我回想此前自己的一个小游戏项目,当时我就遇到过一个困扰:如何使用一段代码统一处理玩家(
Player类)对所有敌人(Enemy类)造成的伤害呢? - 因为我最开始的
Enemy类只有一个子类Bringer,所以我在处理玩家造成的伤害的时候就直接写成了对Bringer造成的伤害,当我向游戏中加入第二个敌人的时候,我就需要在这个脚本内相同位置加入针对这个敌人的伤害检定代码,我当时就觉得很烦,每次添加新的敌人都要考虑到这里要加新代码,万一忘了就会产生Bug - 我当时对C#的多态相关语法不熟悉,就抱着试一试的态度直接将对
Bringer的检测直接改成了其父类Enemy,没想到Unity居然没报错,这一段代码就能帮我处理玩家对所有敌人的伤害
六、接口隔离原则(ISP)
在设计接口的时候要精简单一
6.1 定义
- 接口隔离原则(Interface Segregation Principle):客户端不应该依赖它不需要的接口,一个类对另一个类的依赖应该建立在最小的接口上
- 这意味着接口应当只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来,只有专注地为一个模块提供定制服务,才能建立最小的依赖关系
6.2 背景
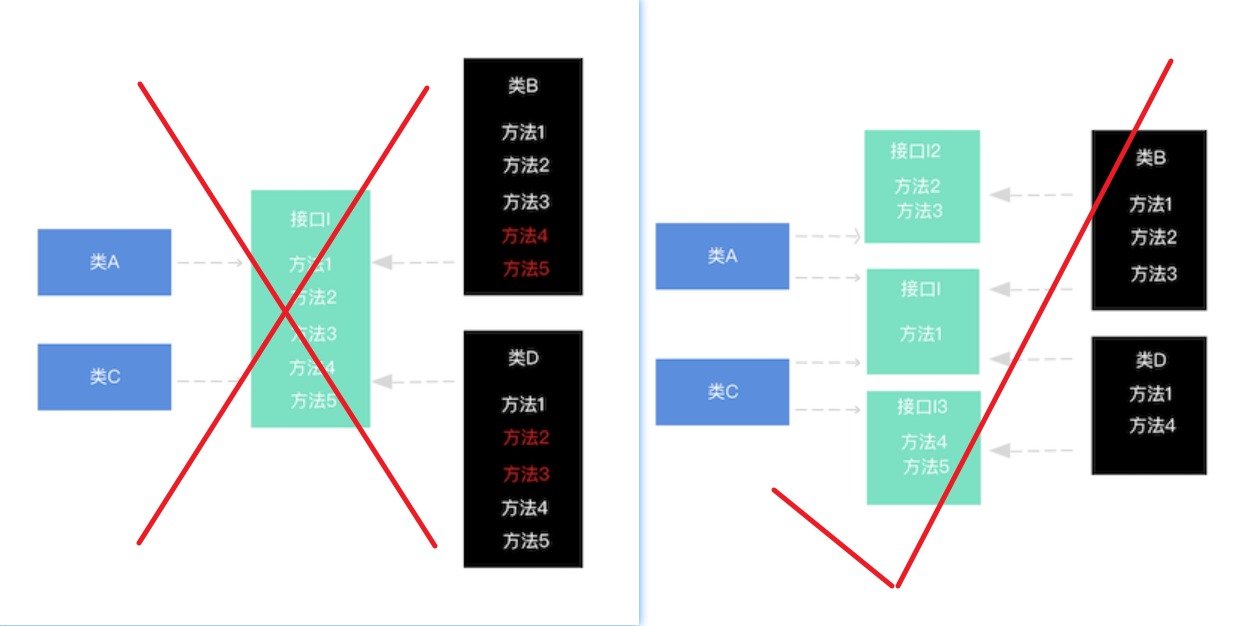
- 类
A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法 - 解决方法就是将
I接口拆分成若干独立接口,类A和类C分别与他们需要的接口建立依赖关系
6.3 注意事项
- 接口尽量小,但是要有限度,对接口进行细化可以提高程序设计灵活性,但是如果过小则会造成接口数量过多而使设计复杂化
- 对比单一职责原则与接口隔离原则
- 单一职责原则原注重的是职责;而接口隔离原则注重对接口依赖的隔离
- 单一职责原则主要是对类进行约束,其次才是接口和方法,它针对的是程序中的实现和细节;而接口隔离原则主要对接口进行约束,主要针对抽象,针对程序整体框架的构建
七、迪米特法则/最少知识原则(LOD/LKP)
要减少不必要的类间通信
7.1 定义
- 迪米特法则(Law Of Demeter)又称最少知识原则(Least Knowledge Principle):如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用
- 迪米特法则强调的是
- 从依赖者的角度来说,只依赖应该依赖的对象
- 从被依赖者的角度说,只暴露应该暴露的方法
- 遵循迪米特法则可以体现在
- 在对其他类的引用上,一个对象对其他对象的引用应当降到最低
- 不暴露类的属性成员,而应该提供相应的访问器(Set和Get方法)
7.2 背景与优点
- 类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大
- 迪米特法则的目的就是降低类之间的耦合度(降低类与类之间的依赖),提高模块的相对独立性,这样的话由于亲合度降低,从而也能提高类的可复用率和系统的扩展性
7.3 案例
- 如果需要打印一个学校所有班级的学生,那么我们设计这三个类的时候不应当让学生类与学校类直接发生通信,而应当按照
School->Class->Student的层次结构来进行通信
7.4 注意事项
- 过度使用迪米特法则会使系统产生大量的中介类,从而增加系统的复杂性,使模块之间的通信效率降低,所以在釆用迪米特法则时需要反复权衡,以确保高内聚和低耦合且系统结构清晰
八、组合/聚合复用原则(CARP)
尽量使用组合或聚合而非继承
8.1 定义
- 组合/聚合复用原则(Composite/Aggregate Reuse Principle):在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分,新对象通过向这些对象的委派达到复用已有功能的目的,简而言之就是尽量使用组合和聚合,而不是继承关系来达到复用的目的
8.2 组合与继承的选取
- 首选组合(满足“Has-A”关系),然后才是继承(满足“Is-A”关系且严格遵守里氏替换原则)
- 详细对比参考此处
8.3 案例
- 比如已知有一个”宝可梦”抽象基类,对于一个同时具有火属性和雷属性的宝可梦A,在实际设计时一般不会设计”火属性宝可梦”派生类、”雷属性宝可梦”派生类然后让”宝可梦A”多继承自这两个派生类,而是设计一个”属性”抽象类并衍生火、雷等属性,然后让”宝可梦A”将属性作为组件包含
本文由作者按照 CC BY-NC-SA 4.0 进行授权