浅析哈希表与哈希碰撞
从哈希表定义引入,介绍哈希函数设计以及哈希碰撞的处理
浅析哈希表与哈希碰撞
一、关于哈希表
1.1 基本读写
- Map是一种存储键值对(Key-Value Pair)的映射结构容器
- Map中的所有键(Key)存在于一个集合(Set)内,集合中的元素是有无序性和唯一性的,所以每个键都是独特的,且相互之间没有储存顺序上的联系
- Map中的值(Value)则不是必须独特唯一的,同一个值可以与多个键建立索引
- Map至少提供以下两个基本操作
Get(key):通过键来获取映射的对应值Put(key,value):新增一对键值对(或覆盖原有的key)
- 哈希表(Hash Table)又称散列表,是一个存放键值对的线性数组,其提供
Hash方法替代Map中的Get与Put,由于是数组作为内核,故其读写时间复杂度为$O(1)$ - 哈希表的新键值对写入流程如下图所示
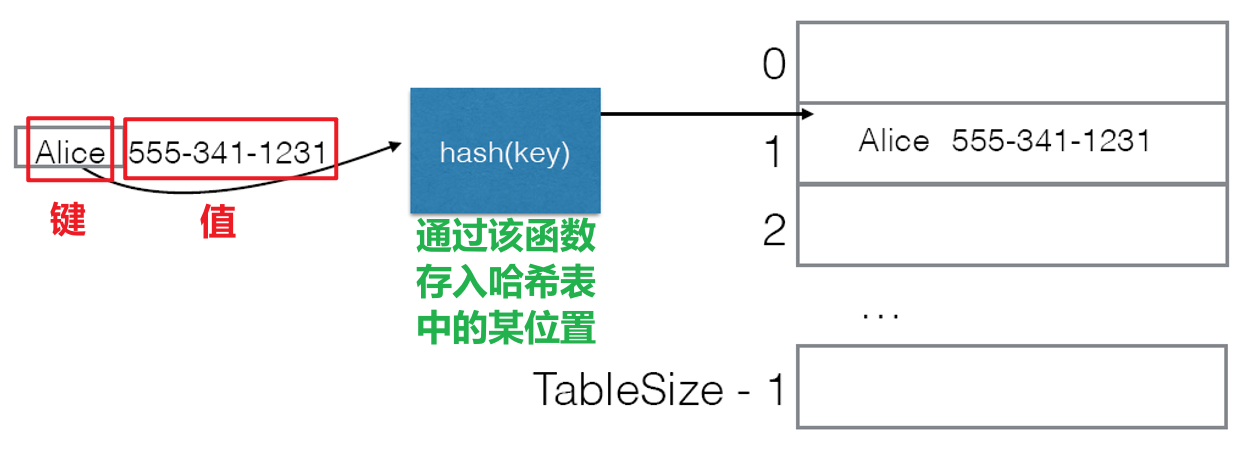
- 哈希表的以键读值流程如下图所示
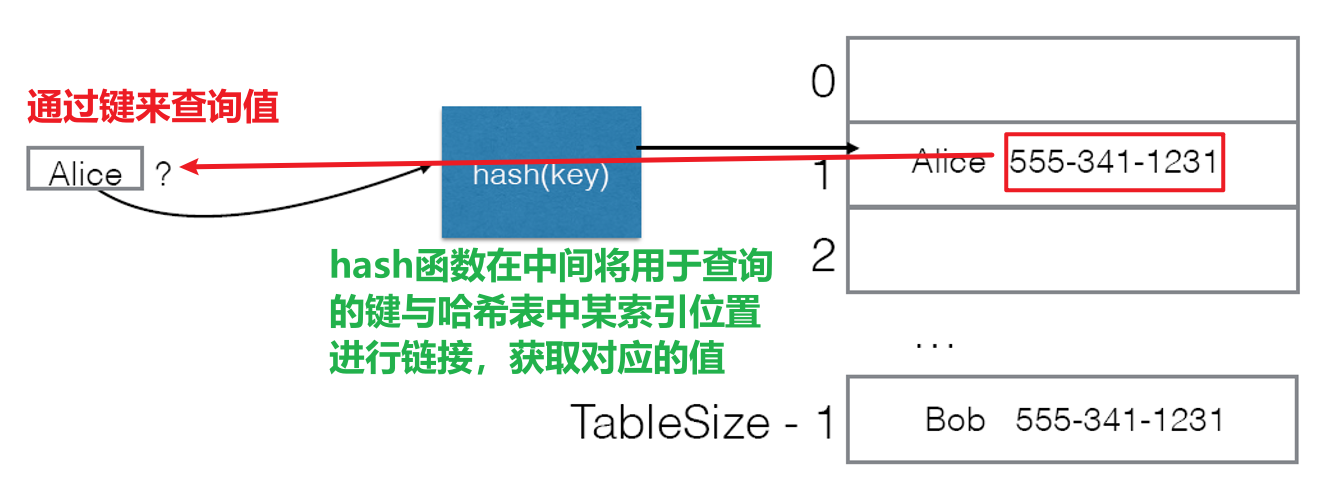
1.2 哈希碰撞
- 若新增的键值对经过哈希函数映射到的索引位置本就存在键值对元素,这就称为哈希冲突或哈希碰撞(Hash Collision),哈希函数应当要能正确处理哈希碰撞,以最大化利用数组空间
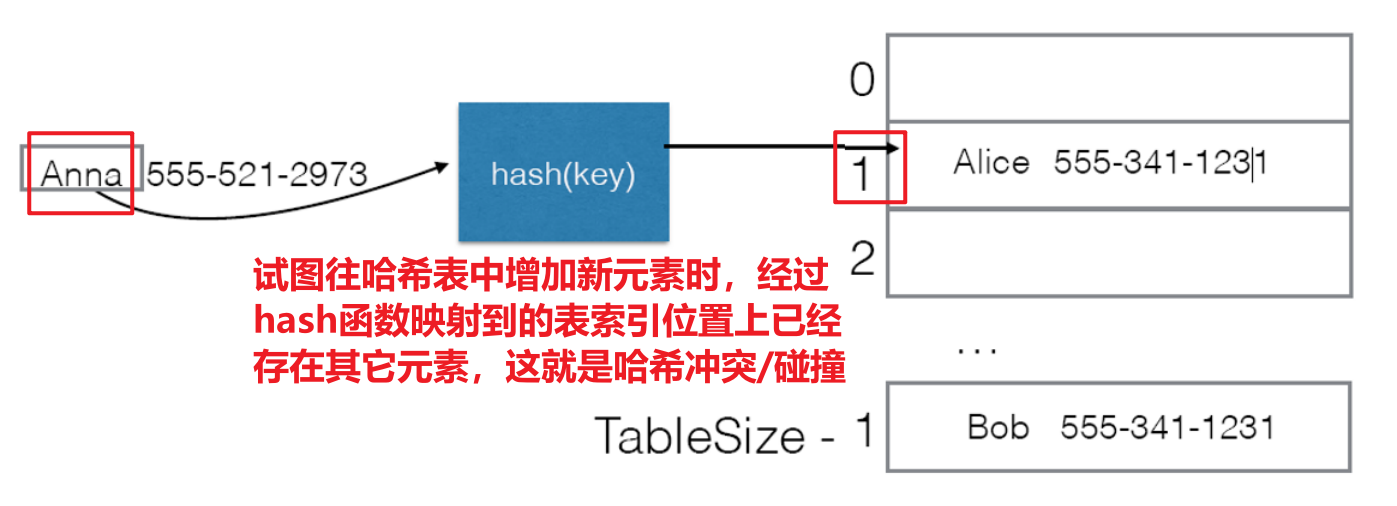
1.3 哈希函数
- 哈希函数的实现取决于键的数据类型以及数组的容量,其实质是将输入的用作读取的键(或是用作写入的键值对中的键)转化为一个整数索引,通过该索引查询哈希表的对应位置,继而可以在该位置读取值(或是存入键值对),其满足以下性质
- 不同的
Key输入能得到不同的Value输出(不同的键值对输入会被存储在数组的不同位置) - 相同的
Key输入能得到相同的Value输出
- 不同的
二、哈希函数设计
2.1 整数键的哈希函数
- 当键的类型为整数时,可以认为所有可能的键是均匀分布的,此时可用取模运算作为哈希函数,即把传入的
Key的大小对数组容量取模,所得的整数即可作为数组索引(这与Cache映射策略中的直接映射使用的哈希函数一致)
1
2
3
4
int Hash(int _key, int _tableSize)
{
return _key % _tableSize;
}
- 取模运算是为了将哈希函数的值限定在数组容量范围内
2.2 字符串键的哈希函数
2.2.1 字符编码求和后取模
- 当键为字符串时,一种哈希方法的思路是将该字符串中的所有字符的ASCII(或Unicode)编码整数值进行相加,将所得的和对数组容量进行取模然后作为索引(例如
"Anna"这个字符串就会被哈希为(65 + 110 + 110 + 97) % _tableSize)
1
2
3
4
5
6
7
int Hash(std::string _key, int _tableSize)
{
int _sum = 0;
for (int i = 0; i < _key.length(); i++)
_sum += _key[i]
return _sum % _tableSize;
}
- 这种哈希函数的缺陷是,对于大容量的数组和长度较短的字符串
Key来说,数组中仅有有限个位置能被哈希映射到,对于这几个被利用到的有限空间来说,极易发生哈希冲突(如字符串中的所有同素异形体”rescued”、”secured”、”seducer”都会发生冲突)
2.2.2 字符编码放大求和
- 若字符串键的长度都较小,那么前一种哈希函数的缺陷的一种解决方法就是将每个字符的编码乘上较大的系数后再相加,将结果直接返回(而不取模)作为索引使用
1
2
3
4
5
6
7
int Hash(std::string _key, int _tableSize)
{
int _sum = 0;
for (int i = 0; i < _key.length(); i++)
_sum += _key[i] * pow(27, i);
return _sum;
}
- 这种方法的缺陷在于,实际情况中的字符串中的字符出现概率并不是均匀的,比如xyz这三个字符出现的就极少,这会导致哈希函数的值域并不能均匀覆盖数组索引空间,增加哈希冲突的概率
2.2.3 多项式哈希
- 下面这种方法称为多项式哈希,其可以使得哈希值分布更均匀,但当字符串键较大时计算较慢
1
2
3
4
5
6
7
8
9
10
int Hash(std::string _key, int _tableSize)
{
int _sum = 0;
for (int i = 0; i < _key.length(); i++)
_sum = 37 * _sum + _key[i];
_sum %= _tableSize;
//防止出现负数索引
if (_sum < 0) _sum += _tableSize;
return _sump;
}
2.3 复合类型键的哈希函数
- 在实际应用中,通常会以自定义的复合类型作为键,此时我们也需要为其设计哈希函数
- 假设该类型的所有成员变量的类型均拥有哈希函数
- 将
Key的所有成员变量的分别通过对应的哈希函数得出整数索引,各乘上不同的大质数后,将结果相加作为该Key的最终索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct Person
{
string firstName;
string lastName;
int age;
}
int Hash(std::string _key, int _tableSize)
{
//将各字段的哈希值乘上大质数系数后相加
int _sum = Hash(_key.firstName, _tableSize) * 127 + Hash(_key.lastName, _tableSize) * 1901 + Hash(_key.age, _tableSize) * 4591;
//取模并归正
_sum % _tableSize;
if (_sum < 0) _sum += _tableSize;
return _sum;
}
- 关于为什么是乘上质数,因为数组的容量是会被用于取模的,所以理想中的哈希函数得出的正整数索引值不应当存在
_tableSize因数,这样才能减少哈希冲突,为此我们需要确保- 数组容量为质数
- 当合并哈希函数时,使用质数作为系数
三、处理哈希冲突
键的数量是可以无限多的,没有任何一种哈希函数设计可以完全避免哈希碰撞,即便发生了碰撞我们也需要想办法将其存入哈希表中
3.1 链表法
3.1.1 每个索引处设置桶
- 我们可以将每个发生冲突的键值对以链表的形式存入相同的索引位置,也就是说这种哈希表的数组存放的元素是以键值对为元素的链表桶,这就是解决哈希冲突的链表法(Chaining)
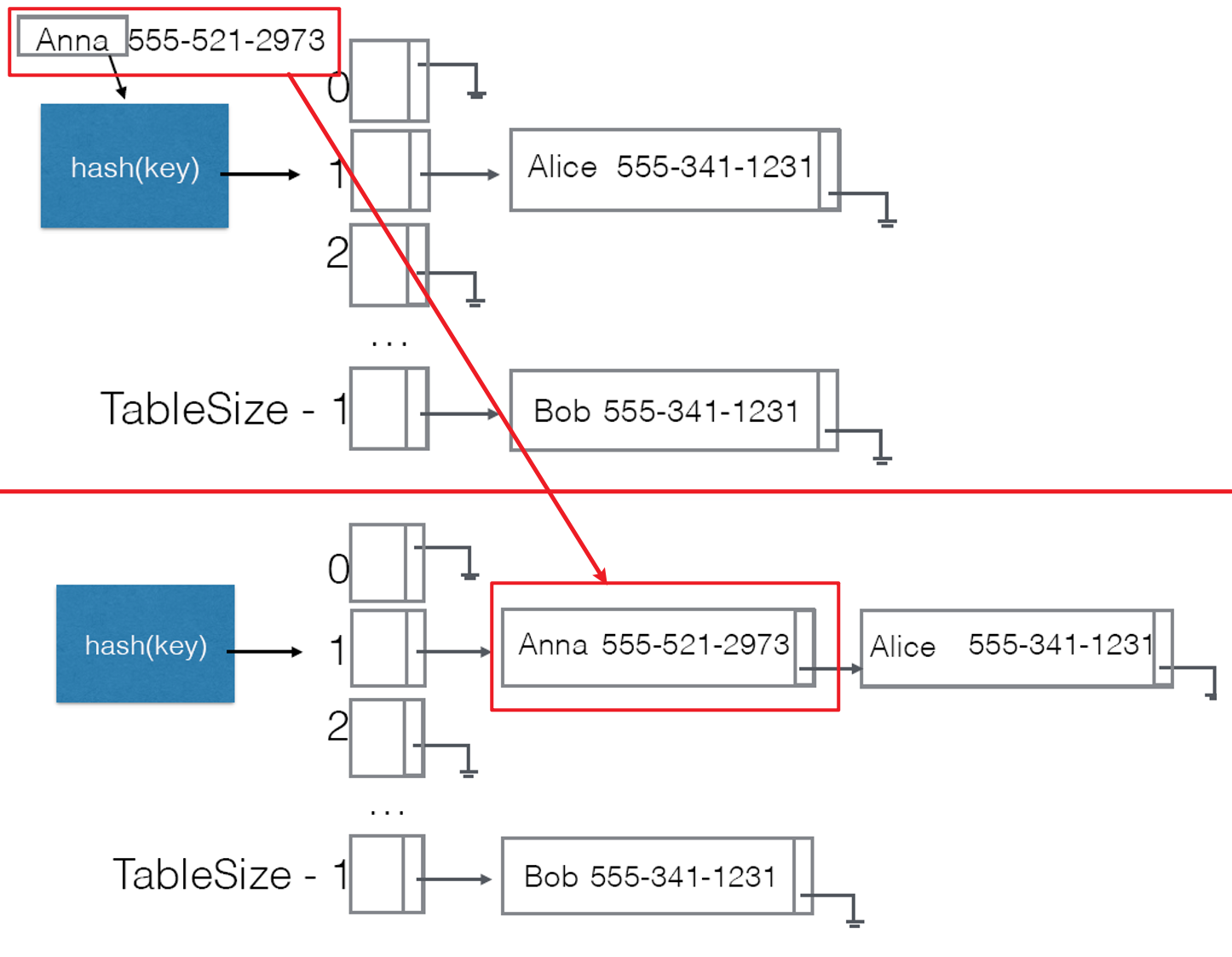
- 这种方式的缺点就是:需额外编写代码以引入更为复杂的节点(存放键值对的链表桶节点)数据结构设计,并且还需要实现链表的遍历
3.1.2 时间复杂度
- 这种方式所需的映射时间=计算哈希函数值的时间+遍历对应位置链表的时间,其中计算哈希值的时间这部分此处不做讨论,我们从另一部分的角度上来分析时间复杂度
- 假设上述实现的哈希表中存在$N$个Key,则定义Load Factor如下,每个桶链表的平均长度为$\lambda$
- 实际通过Key访问哈希表的对应索引位置的桶时
- 若未找到对应Key(即Table Miss):说明已经遍历了对应索引处的链表内的$\lambda$个元素
- 若找到了对应Key(即Table Hit):则平均需要遍历$\frac{\lambda}{2}+1$个元素以找到目标
- 所以为了减少遍历链表所带来的时间复杂度开销,最好确保哈希函数能使得$\lambda\approx1$,即尽可能地减少哈希碰撞,使得键值对均匀分布在哈希表数组中
3.2 开放寻址法
开放寻址法(Open Adressing)包括三种方法,其区别在于遇到哈希冲突时以怎样的步长在哈希表中依据冲突的位置
3.2.1 线性探索法
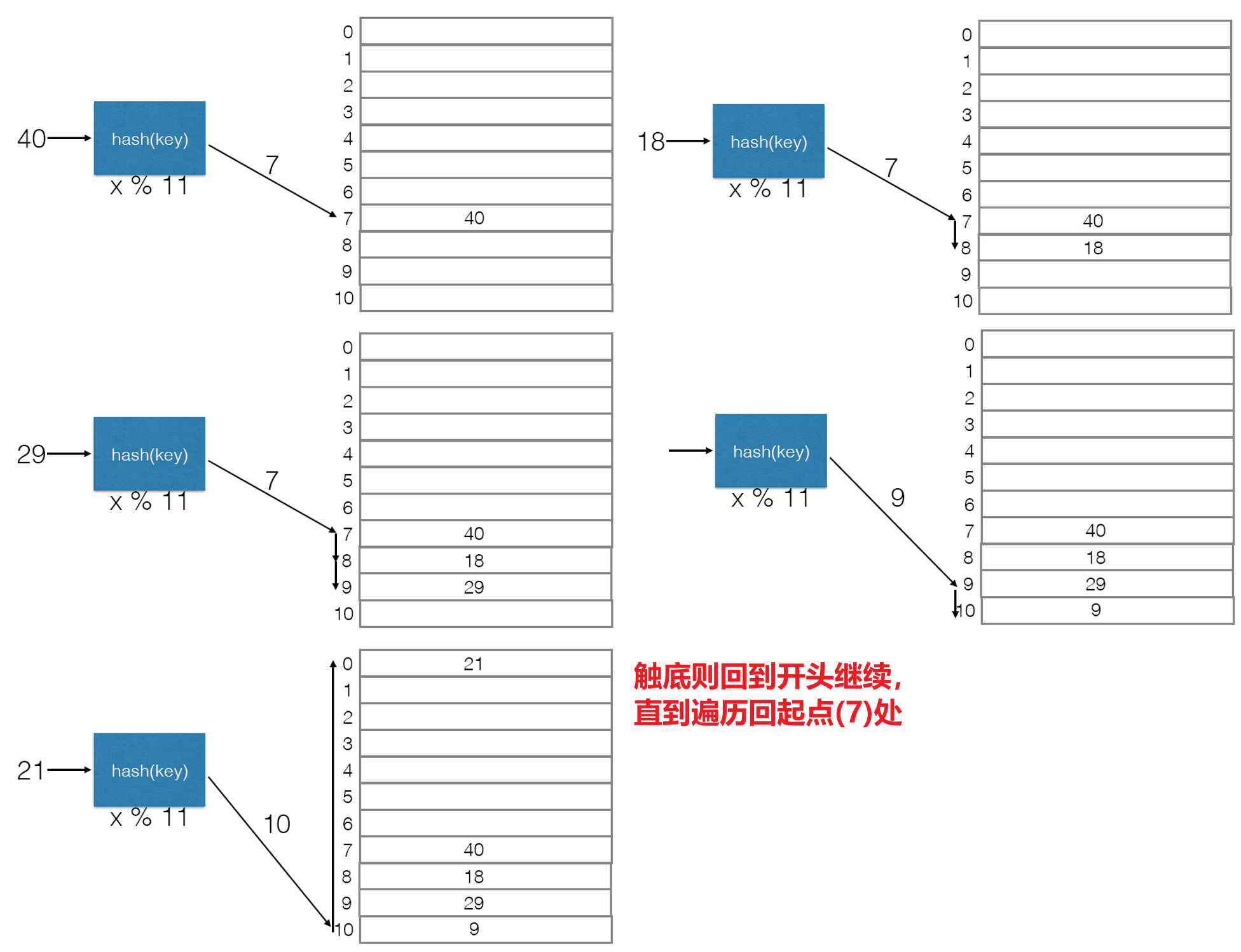
- 若将一个新的键值对存入哈希表时发生了哈希碰撞,则线性探索法(Linear Probing)会按照固定的步长(通常取$1$)依次检查哈希表中的下一个位置,若碰到列表底部则继续从列表的$0$索引位置开始探索,直至找到空闲位置将键值对存入为止(或遍历回最开始发生冲突的起点位置,说明列表中没有空位了)
- 可以看出,当$\lambda=1$时,即便所有插入的键值对全部冲突在一个位置,哈希表也会是被填满的
- 这种方式实现的哈希表在被读取时,同一个Key依然能映射出唯一的一个Value,只不过对应的键值对在哈希表中的位置并非一定是固定的罢了
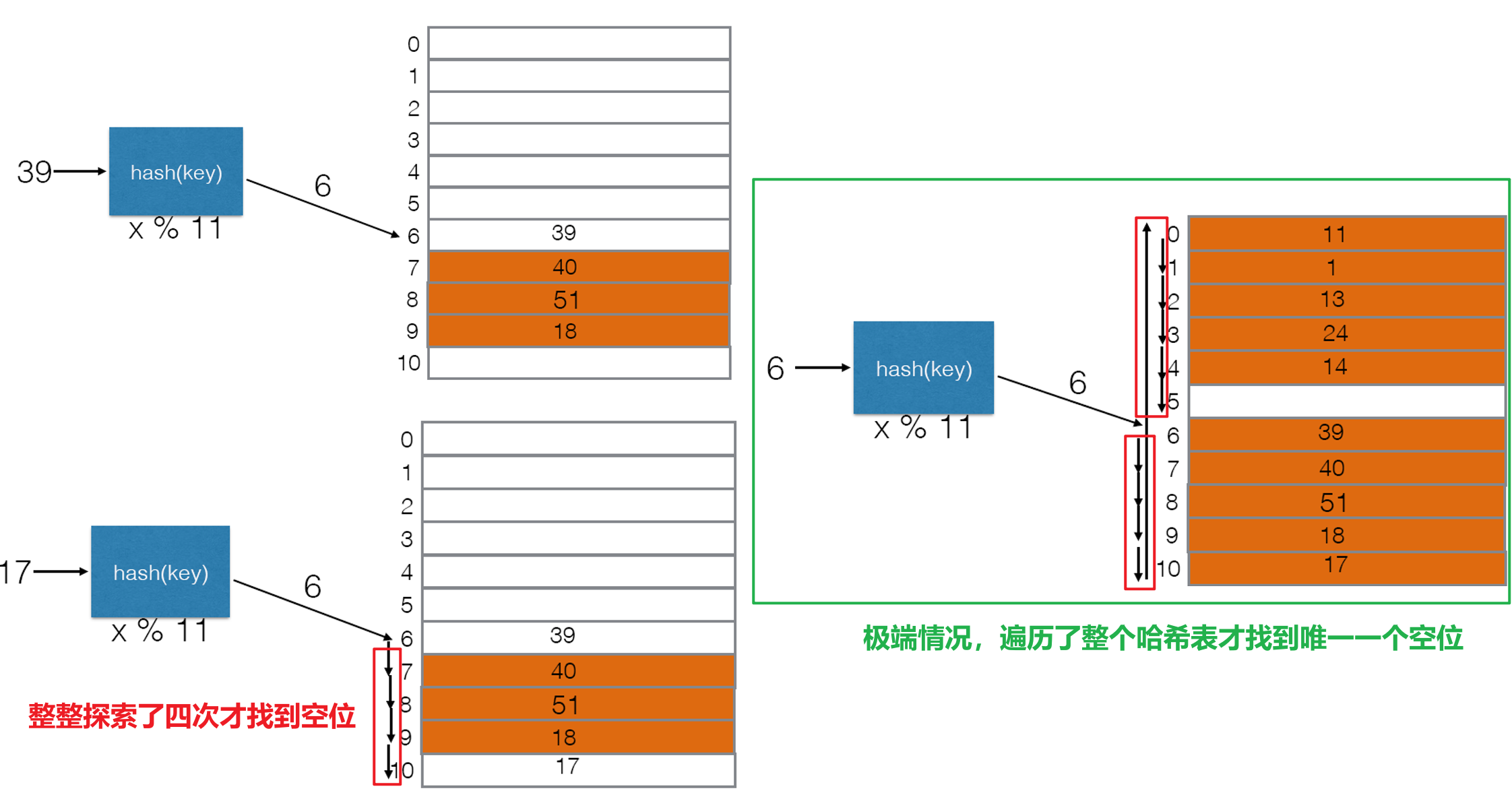
- 这种方法容易由于元素群聚(Clustering)而导致哈希冲突时寻找新空位的时间开销较高,极端情况下甚至可能需要遍历整个哈希表,如下图所示
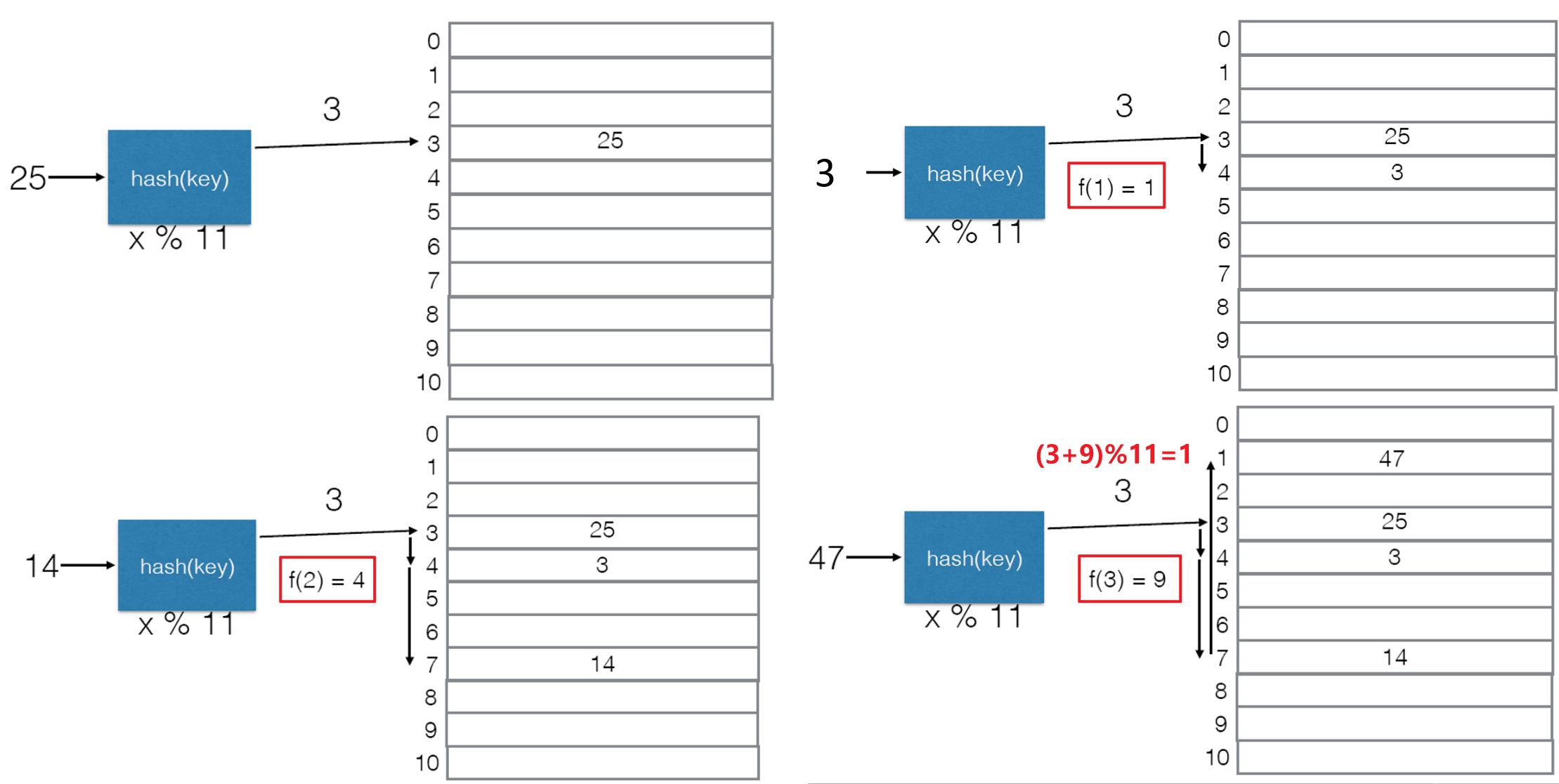
3.2.2 二次探索法
- 我们重新对线性探索法进行分析,其确定冲突的键值对最终被存入的位置的索引值可由下式推出
- 对于线性探索法,下式中使用$f(i)=i$
- 其中$i=0$相当于未发生冲突,此处探讨的是发生冲突后如何寻找新空位的索引
- 从$i=1$开始递增使用$i=2,3,4,…$带入式中求解$Index$
- 直到找到空位,或发现哈希表是满的而无法插入
- 二次探索法(Quadratic Probing)使用基于二次函数$f(i)=i^2$递增的步长来寻找下一个位置,这种方法能有效避免线性探索中的Clustering问题
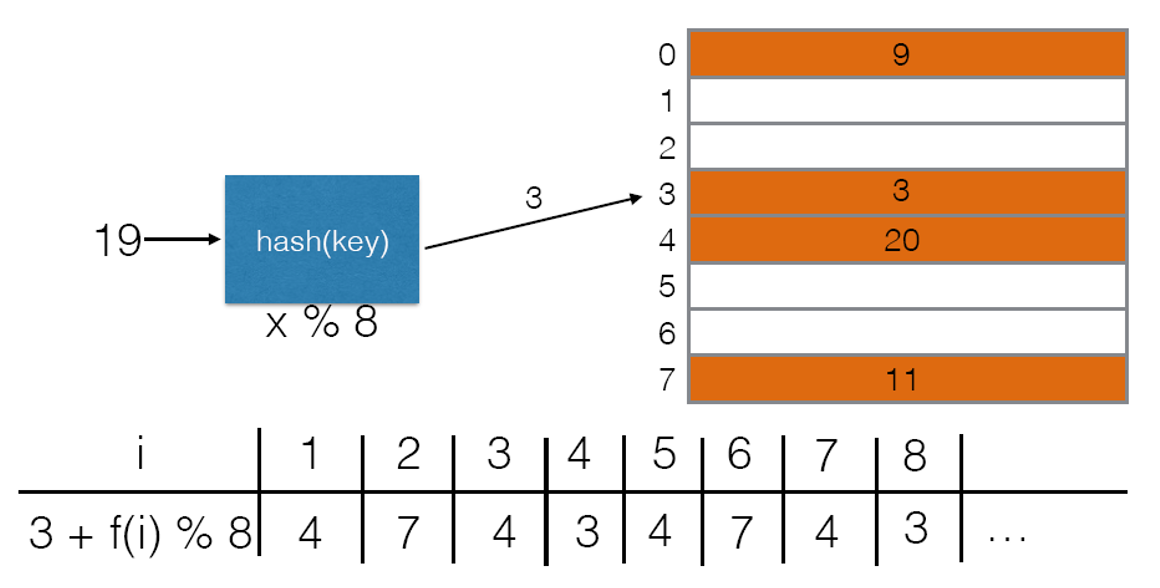
- 二次探索法存在以下注意事项和问题
- 一定要注意使用二次探索法时一定要确保哈希表长为质数,否则即便空位有很多,也可能永远也找不到空位,如下第一张图展示了表长为非素数$8$时,冲突位置在$3$索引处时通过二次探索得到的新索引,可以看到这些值陷入了周期性的局限范围内
- 当空位本就很少时($\lambda>0.5$),即便表长为质数,也可能很难找到空位,如下第二张图中表长为质数$11$时在索引$0$处发生冲突,通过二次探索法找了七八次都没找到空位
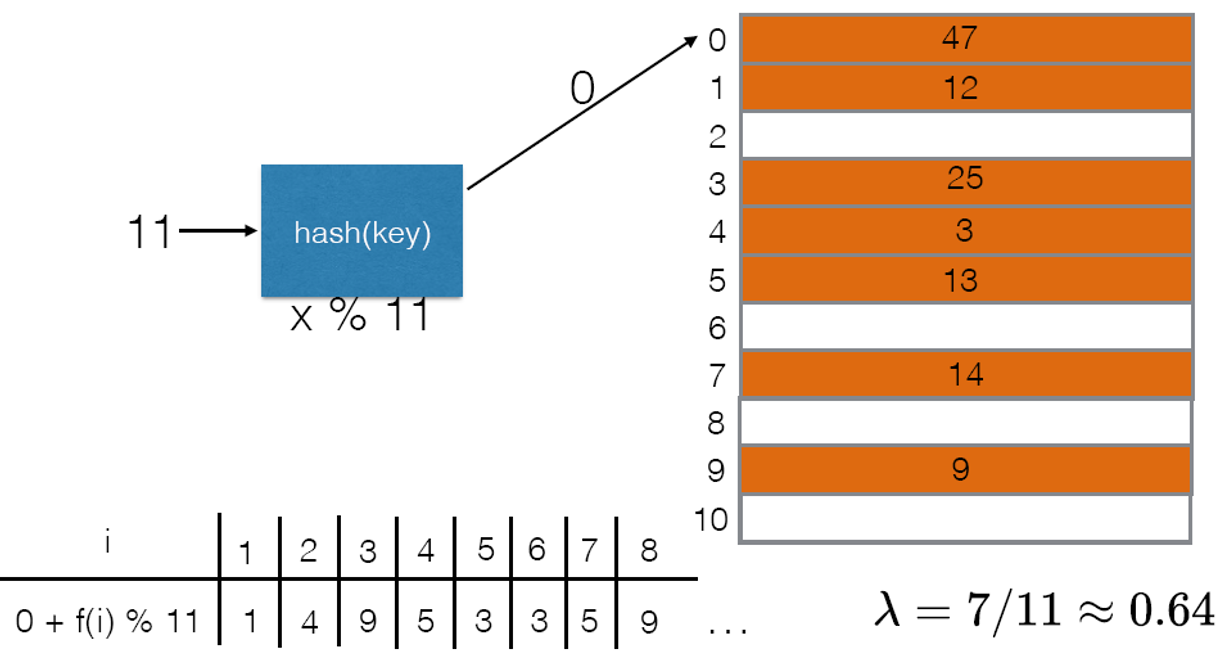
- 下图证明了$\lambda<0.5$时二次探索法一定能找到空位

3.2.3 双重哈希法
- 双重哈希(Double Hashing)不是简单地递增步长,而是使用另一个独立的哈希函数来计算探测的步长,相当于使用函数$f(i)=i\cdot Hash_2(Key)$带入下式中计算新的索引位置
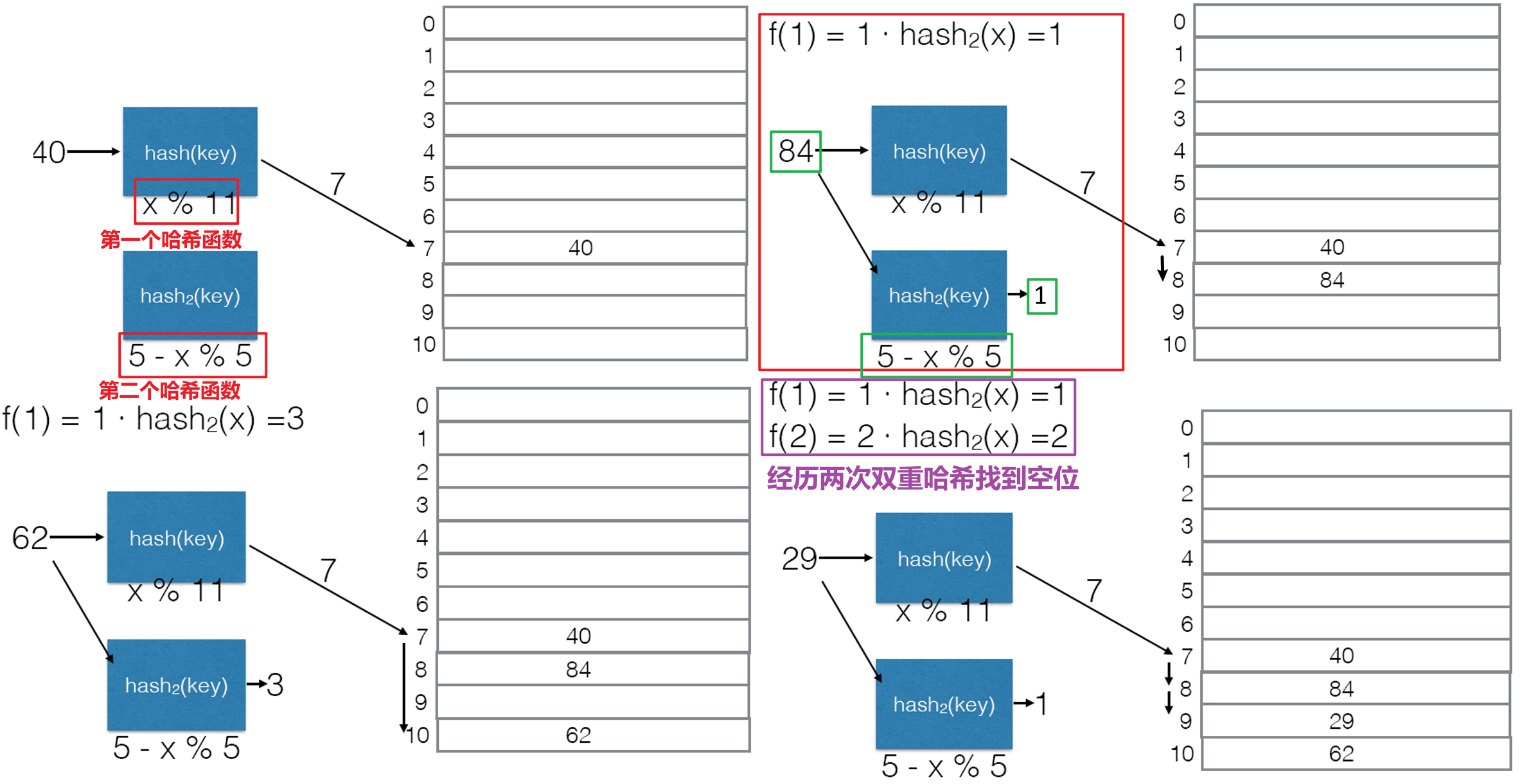
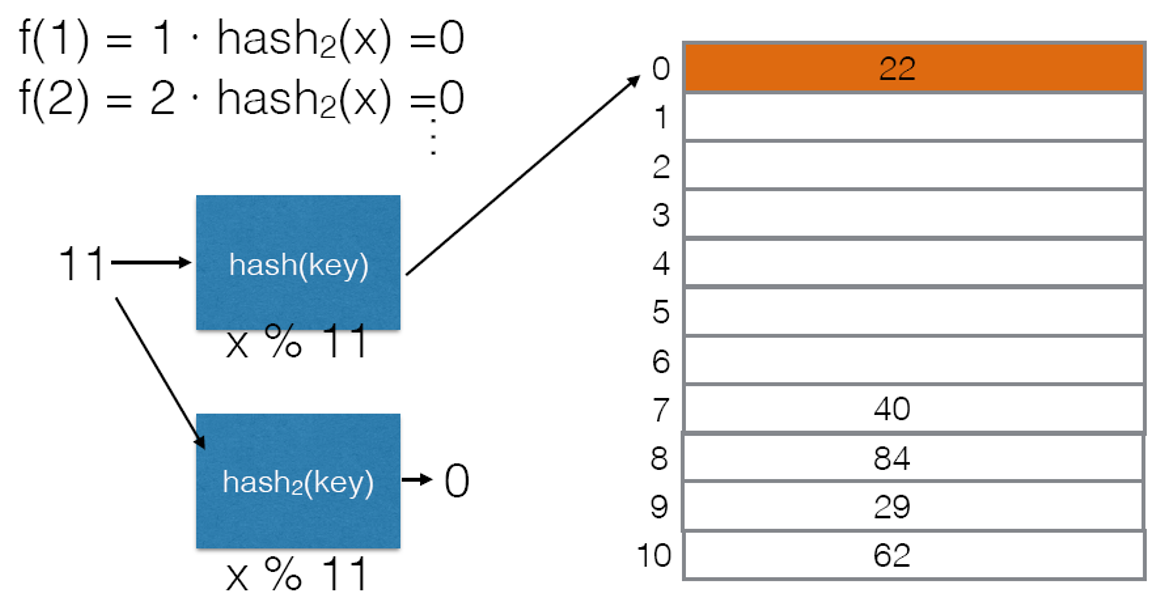
- 第二个哈希函数的选取应当要与第一个有所差异,否则会出现下图的问题,整数键的第二个哈希函数使用$Hash_2(i)=R-(x\% R)$是个不错的选择
3.3 重哈希
- 我们发现哈希表的表长$TableSize$是一个影响哈希表效率的很关键的因素
- 链表法中:$TableSize$过小会导致冲突概率增大,导致链表平均长度$\lambda$过大,时间效率降低
- 线性探索法中:$TableSize$过小会导致$\lambda$过大,从而增大Clutering发生的概率,时间效率降低
- 二次探索法中:$\lambda>0.5$会导致找不到空位,导致哈希表的空间利用效率降低
- 所以当我们发现$\lambda$过大时,可以将原哈希表中的键值对全部转移到另一个更大容量的(通常是$2$倍表长的)哈希表中(表长改变会导致哈希函数改变,所以转移元素时需使用新哈希函数),这种方法叫做重哈希(Rehashing)
- 我们通常会在表中元素数量达到了$\frac{TableSize}{2}$(即$\lambda=0.5$)时进行重哈希以避免哈希碰撞,通过这种方式,我们可以认为平时向表中新增元素时不发生碰撞,即仅需$O(1)$时间复杂度,而仅在很少的情况下会需要进行复杂度为$O(TableSize)$的转移元素操作
本文由作者按照 CC BY-NC-SA 4.0 进行授权