处理器执行程序与指令的流程详解
程序由一系列指令组成,故若欲明白程序的执行,必须先明白指令的执行流程,所以本博客通过经典的处理器架构,详细分析处理器的内部硬件结构、指令执行过程中各元器件的工作逻辑、控制信号的产生等,以帮助读者对指令执行形成较全面的理解
处理器执行程序与指令的流程详解
在阅读此篇笔记之前,请先确保理解了这篇关于指令集体系结构的博客中的知识:ISA中的指令格式设计与寻址模式
一、程序的运行流程
- 程序就是一连串的指令序列,我们需要按照一定的规则和顺序来执行这些指令序列
- 处理器(Processing Unit、Instruction Set Processor、Central Processing Unit/CPU)执行指令的流程示意如下图所示,第一、二步合称拉取循环,第三步为执行循环
- 第一步:拉取PC指向的地址内容(初始化为程序起点),这块内存的内容被加载到IR
- 其中PC是程序计数器,指向当前程序进行到了哪一条指令,提供其地址
- 其中IR是指令寄存器,用于存储当前应当被执行的指令
- 第二步:递增PC,让其指向下一条指令
- 假设内存以字节编址,每个指令占$4$字节,则PC自增表示为$PC\leftarrow[PC]+4$
- 第三步:执行IR中存储的指令
- 第一步:拉取PC指向的地址内容(初始化为程序起点),这块内存的内容被加载到IR
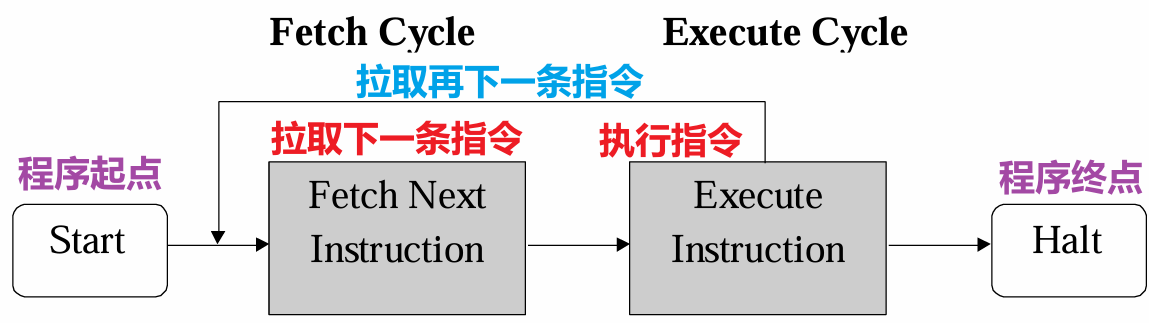
- 如果单个指令占用的空间大于内存中的单个Word的大小(即单次拉取的大小上限),则上述的步骤一、二需要被执行多次来确保拉取完整的指令
二、指令的执行流程
2.1 指令的分步执行
2.1.1 RISC指令的五步执行
- 指令$Load\space R_B\space R_A$的执行过程由复杂的硬件逻辑电路运行,该过程会被分解为更小的步骤,以分步执行整个指令,这样的系统被称为管线(Pipline)
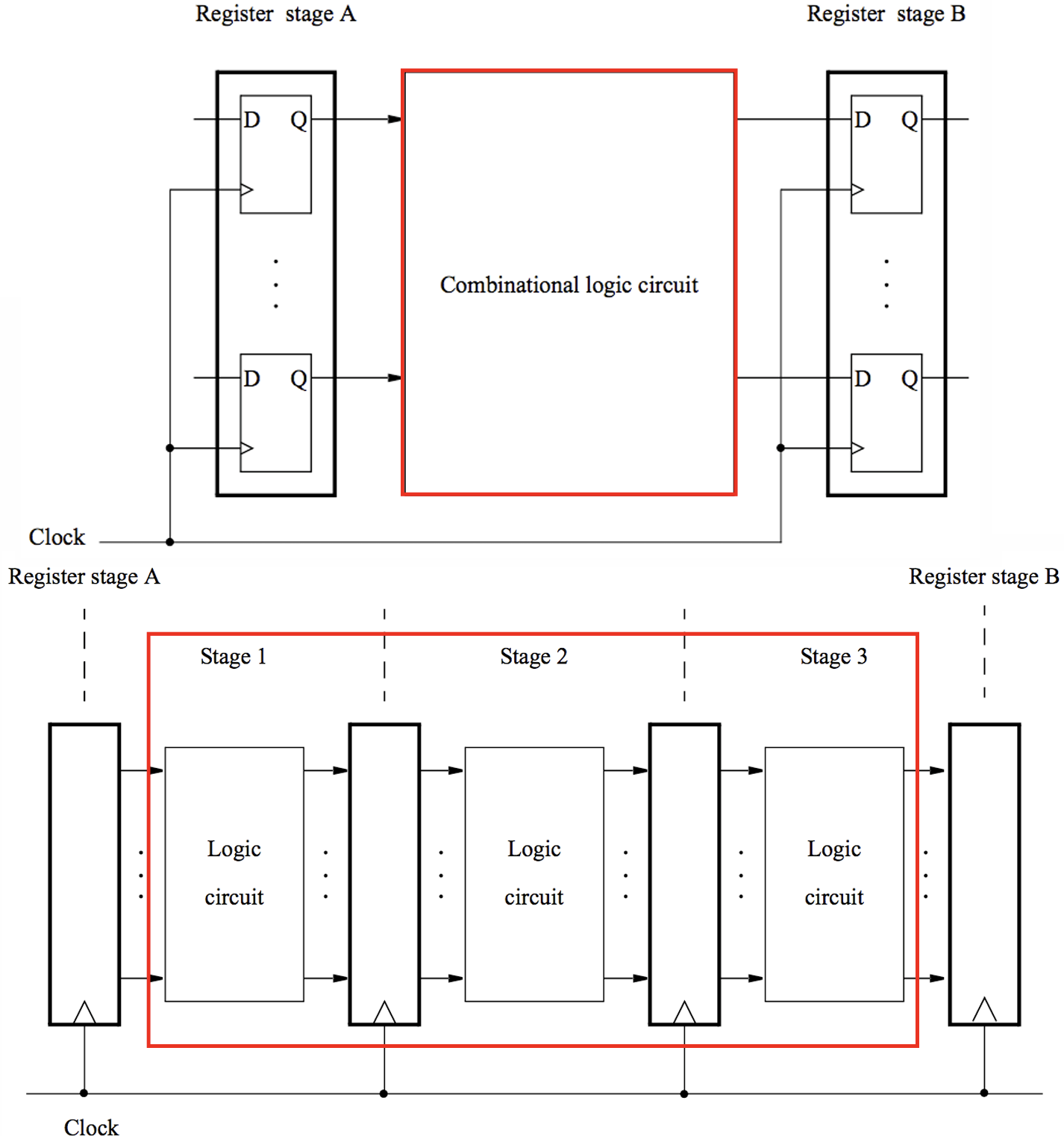
- 当所有指令操作的子步骤数相同时,管线运行效率最高,RISC处理器中指令操作统一为$5$步
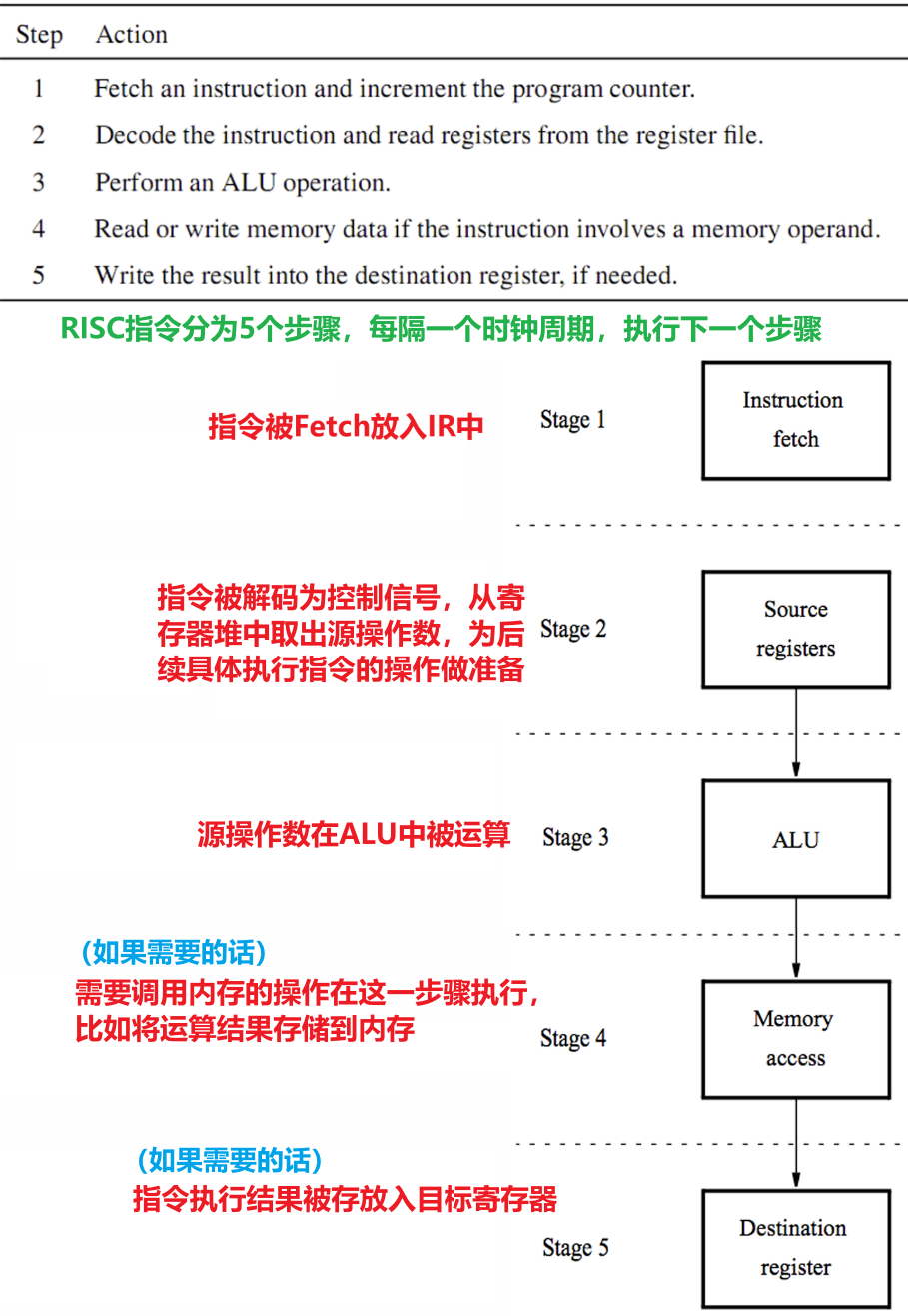
2.1.2 RISC指令的执行示例
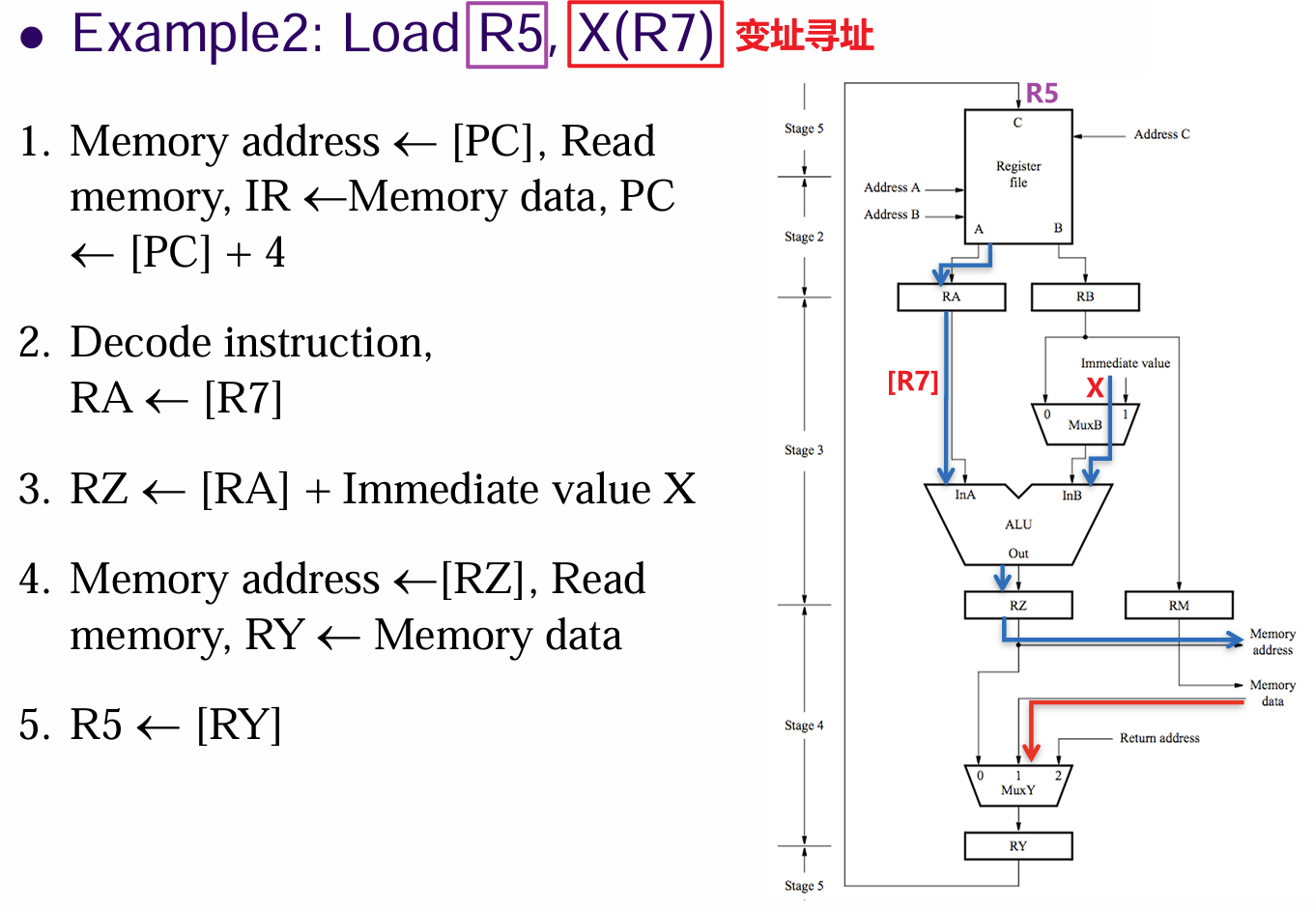
- 以变址寻址的
Load R5, X(R7)为例,执行将内存X+[R7]处的内存数据加载到R5寄存器上- 一:拉取指令到IR、递增PC
- 二:解码指令,读取
R7寄存器内容 - 三:计算
X+[R7]地址 - 四:读取内存
X+[R7]处的源操作数 - 五:加载操作数到目标寄存器
R5
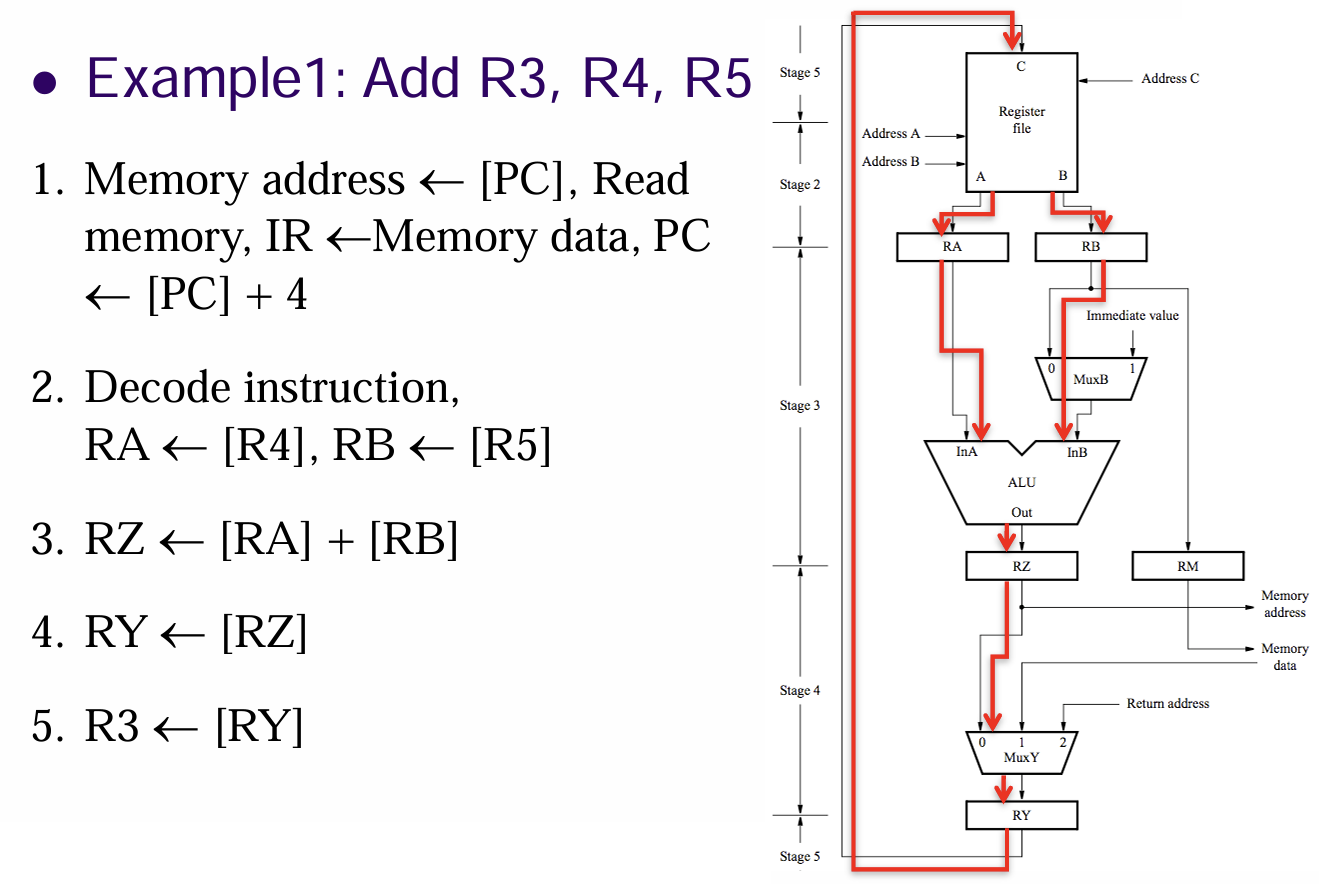
- 以寄存器寻址的加法指令
Add R3, R4, R5为例,其仅有4步(因为操作数都在寄存器内,故少了第四步的加载内存中的数据的步骤),但为了统一需要将其扩为5步- 一:拉取指令到IR、递增PC
- 二:解码指令,读取
R4, R5寄存器内容 - 三:计算
[R4]+[R5]之和 - 四:无操作,仅为填充步骤数
- 五:将计算结果加载到
R3寄存器
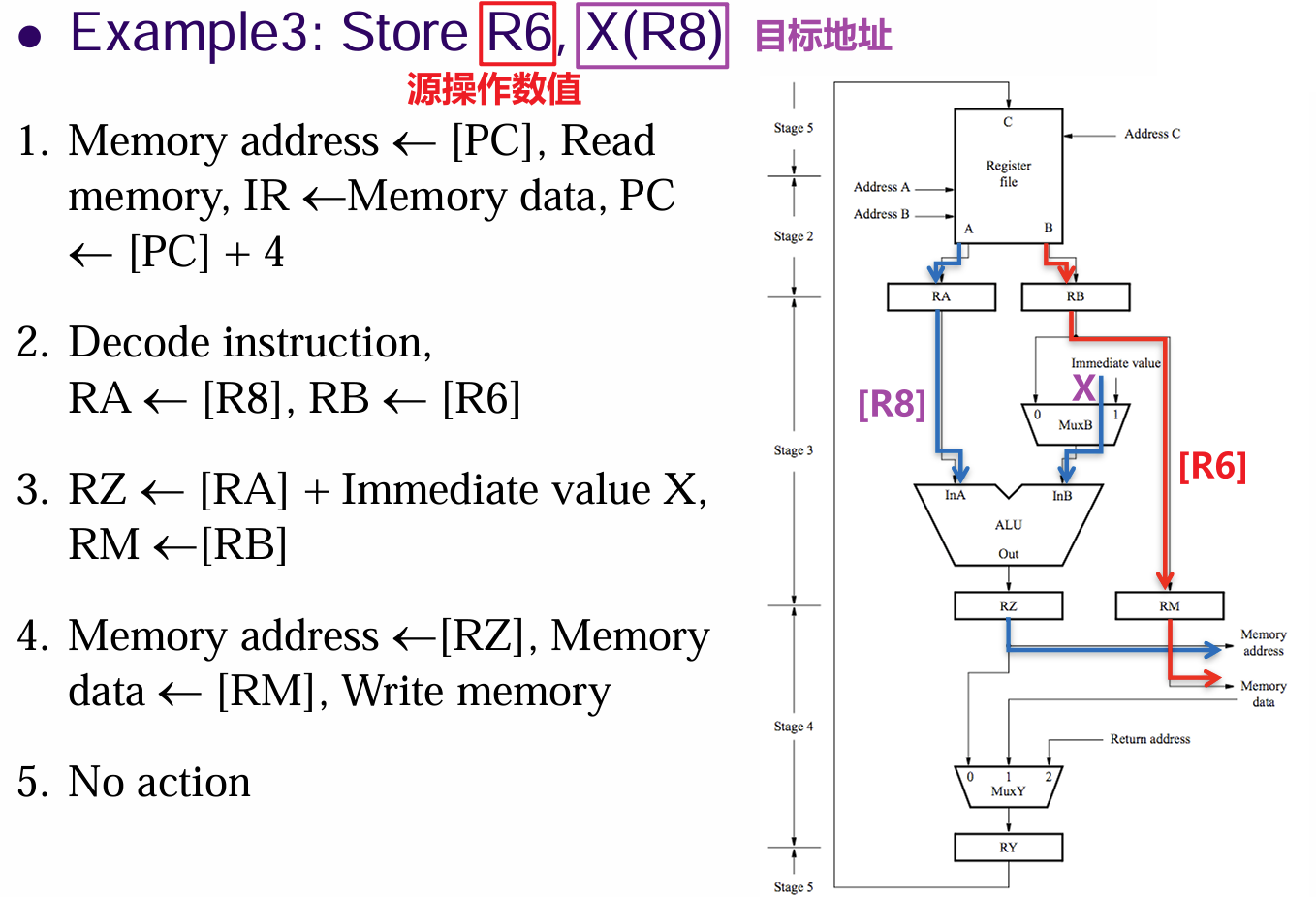
- 以
Store R6, X(R8)为例,其将寄存器R6的数据存储到内存X+[R8]处,其仅有4步(因为不像Load需要将从内存中加载到寄存器那样分为两步,先读取内存,再加载到寄存器,从寄存器拿取数据存放到内存中的已知地址仅需一步),但为了统一同样要将其扩为5步- 一:拉取指令到IR、递增PC
- 二:解码指令,读取
R6, R8寄存器内容 - 三:计算
X+[R8]地址 - 四:存储
R6的内容到内存X+[R8]处 - 五:无操作,仅为填充步骤数
2.2 执行指令的硬件
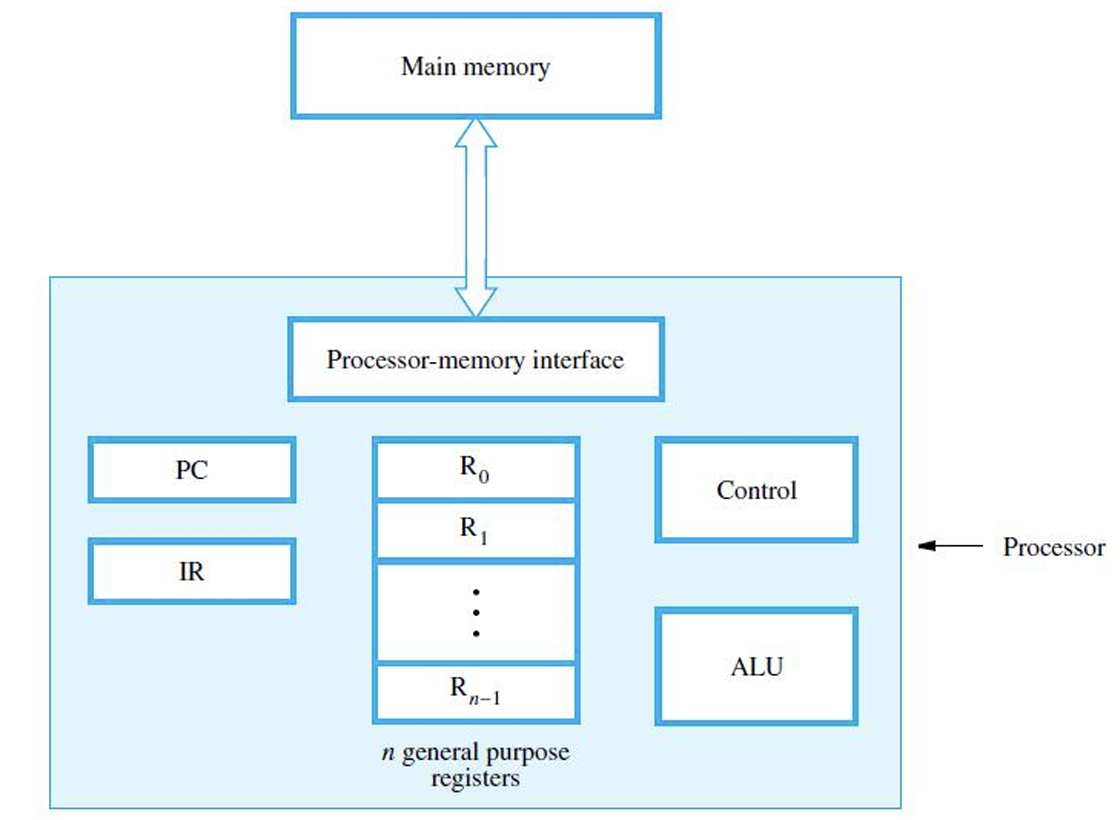
2.2.1 主要硬件组件
- Instruction Address Generator:更新其体内PC指向的指令地址
- 程序计数器(PC, Program Counter):提供指令地址
- 指令寄存器(IR, Instruction Register):存储被从PC拉取的指令内容
- 寄存器堆/寄存器文件(Register File):即CPU内部的寄存器阵列
- 算术逻辑单元(ALU, Arithmatic Logic Unit):处理算术运算与逻辑运算
- Conrtol Circuitry:翻译指令产生控制信号,以具体执行指令
- Processor-Memory Interface:处理器执行指令过程中访问内存时的所用的接口
2.2.2 寄存器堆
- 寄存器堆/寄存器文件(Register File)是处于处理器内的寄存器阵列(如$R_0,…,R_5$),是ISA系统的一部分,其内寄存器用于存储指令操作所需的操作数
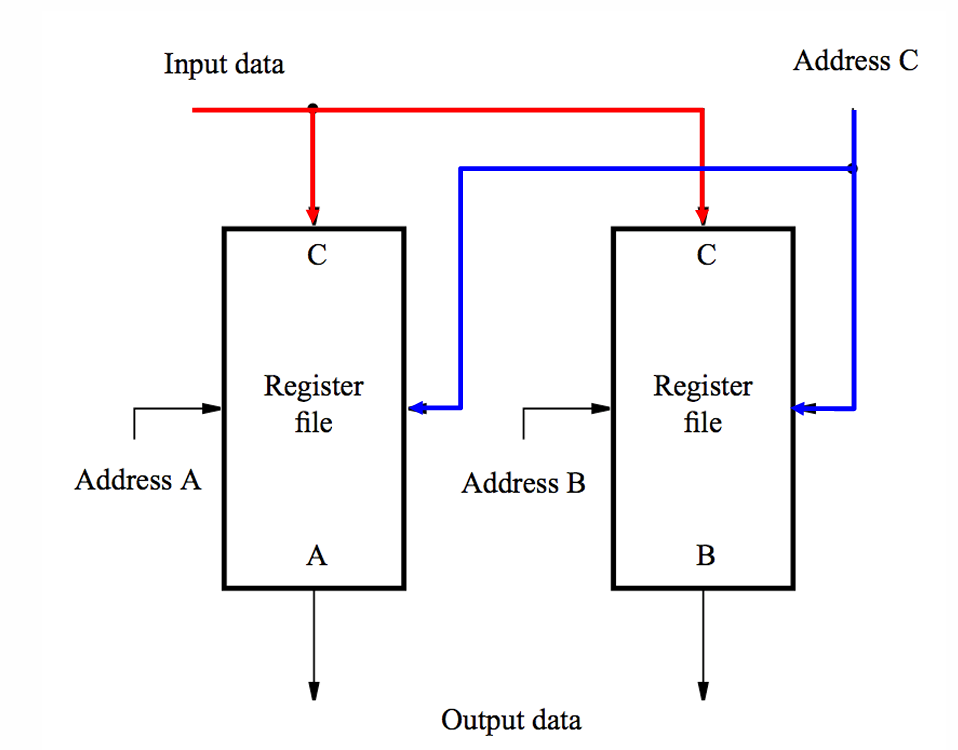
- 如下图所示的是一个双端口(2-Port)的寄存器堆,以指令$XXX\space R_{dstC}\space R_{srcA}\space R_{srcB}$为例
- 其接收三个个地址,其中$A$与$B$寻址源寄存器$R_{srcA}$与$R_{srcB}$,而$C$寻址目标寄存器$R_{dstC}$
- 找到两个源寄存器后,其内数据被取出(即下图的$A$与$B$输出)用以执行指令中的操作
- 对两个源操作数完成运算后,返回值$C$被存入$R_{dstC}$寄存器内
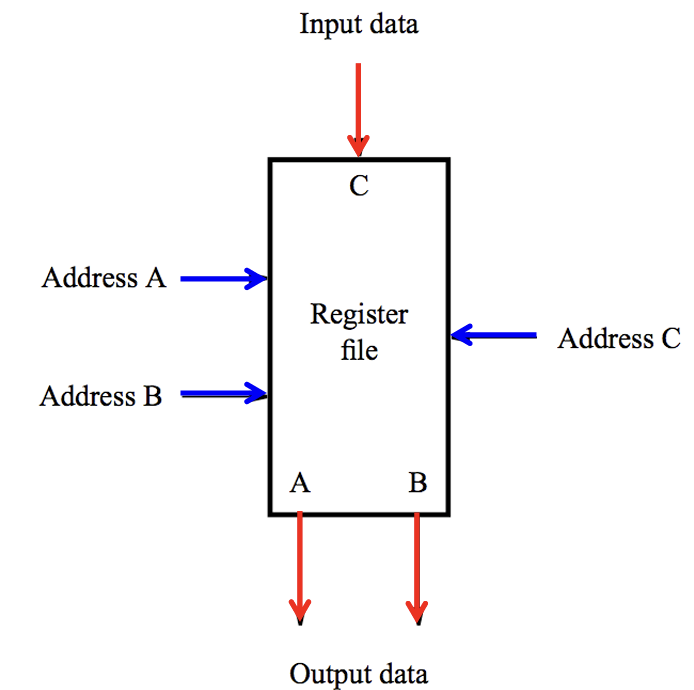
- 可以使用两个单端口的寄存器文件来组成双端口寄存器文件
2.2.3 算术逻辑单元
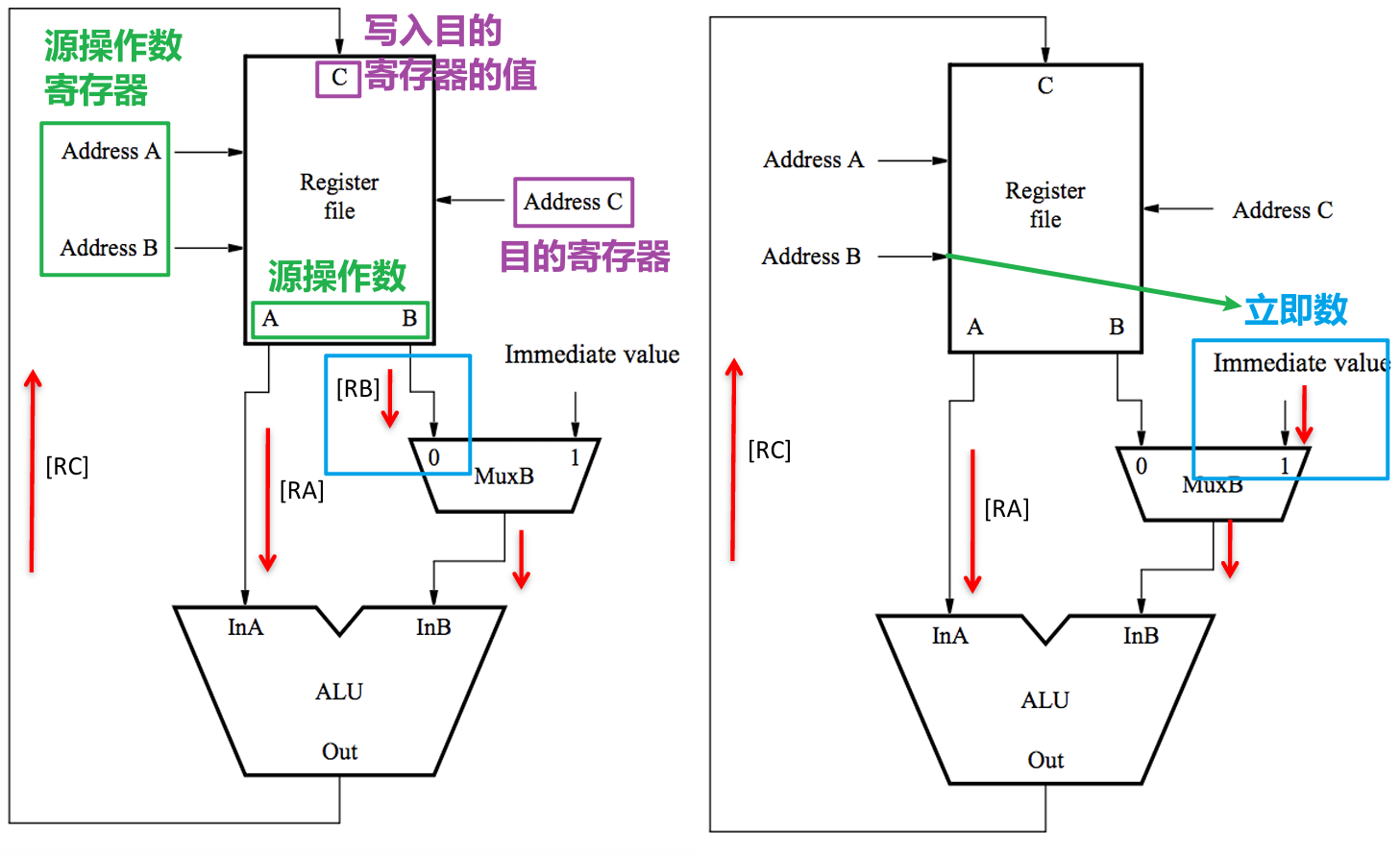
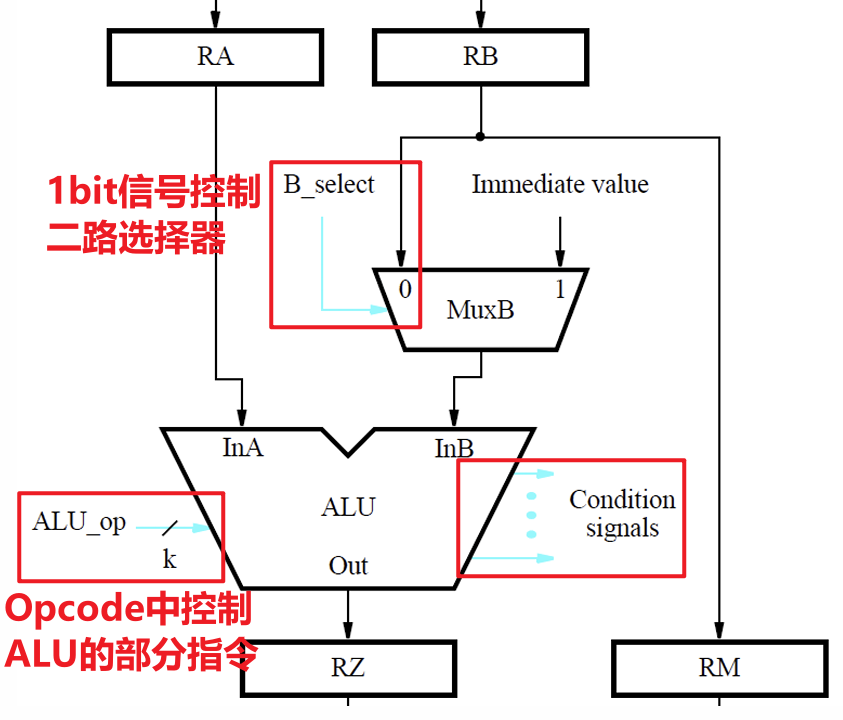
- 算术逻辑单元提供对两个输入值的算术或按位逻辑运算
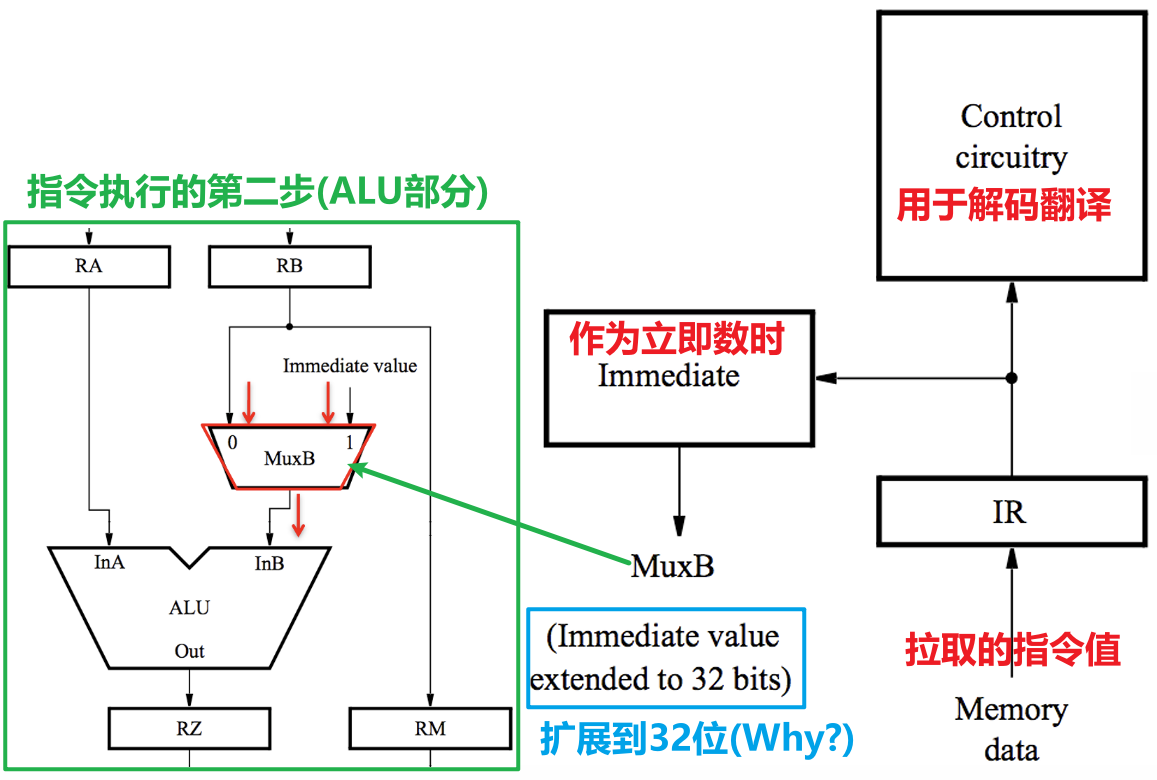
- 下图表示的是ALU对指令$XXX\space Addr_C\space Addr_A\space Addr_B$中运算操作$XXX$的执行,其中左侧是取用寄存器堆中对应地址处的寄存器内的数据用作计算,右侧是将外界传入的立即数用于计算
2.3 数据传递路线
- 指令被分为五步执行的过程中,我们从下图中可以看到数据在每个步骤中流动的情况
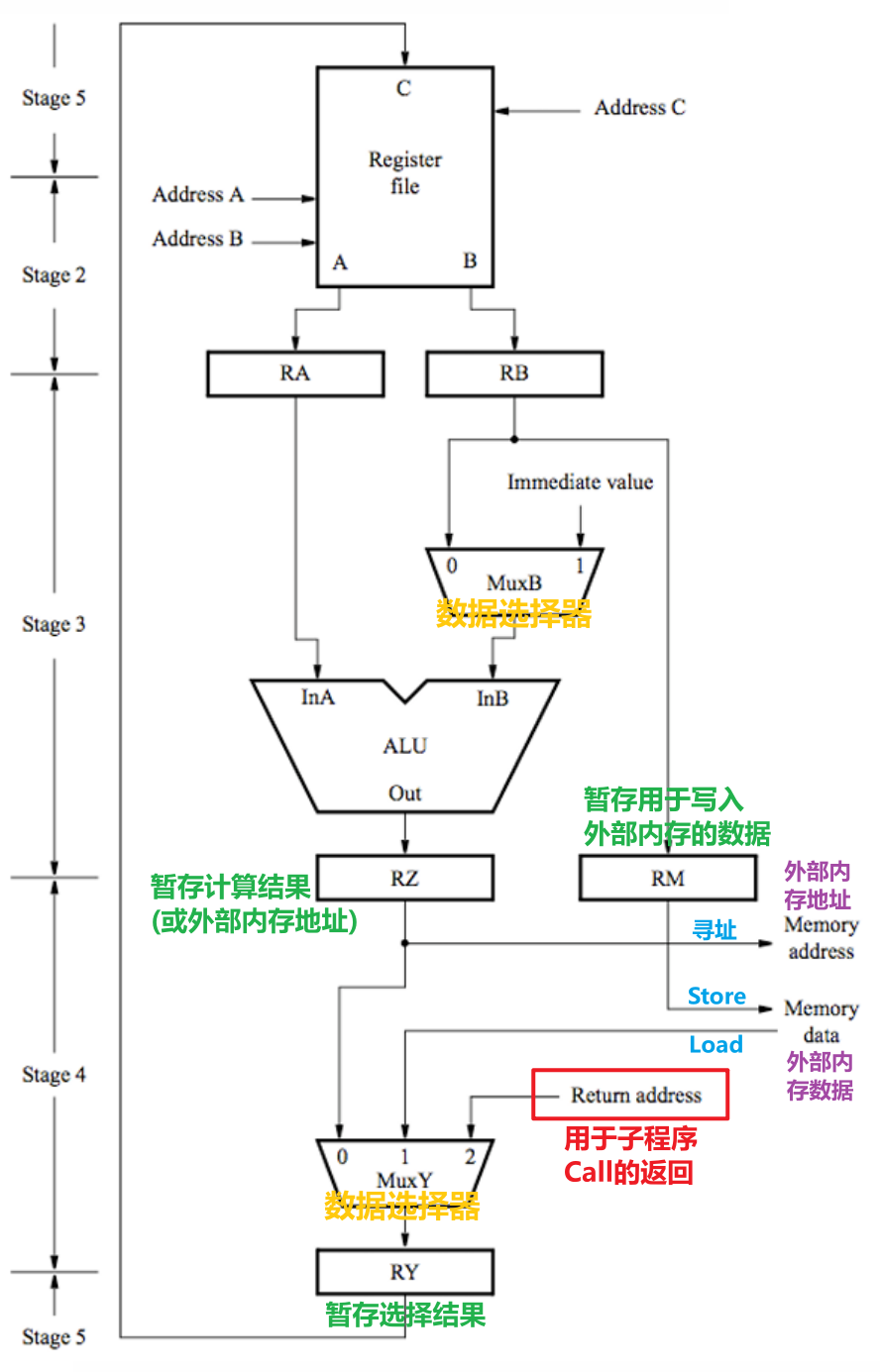
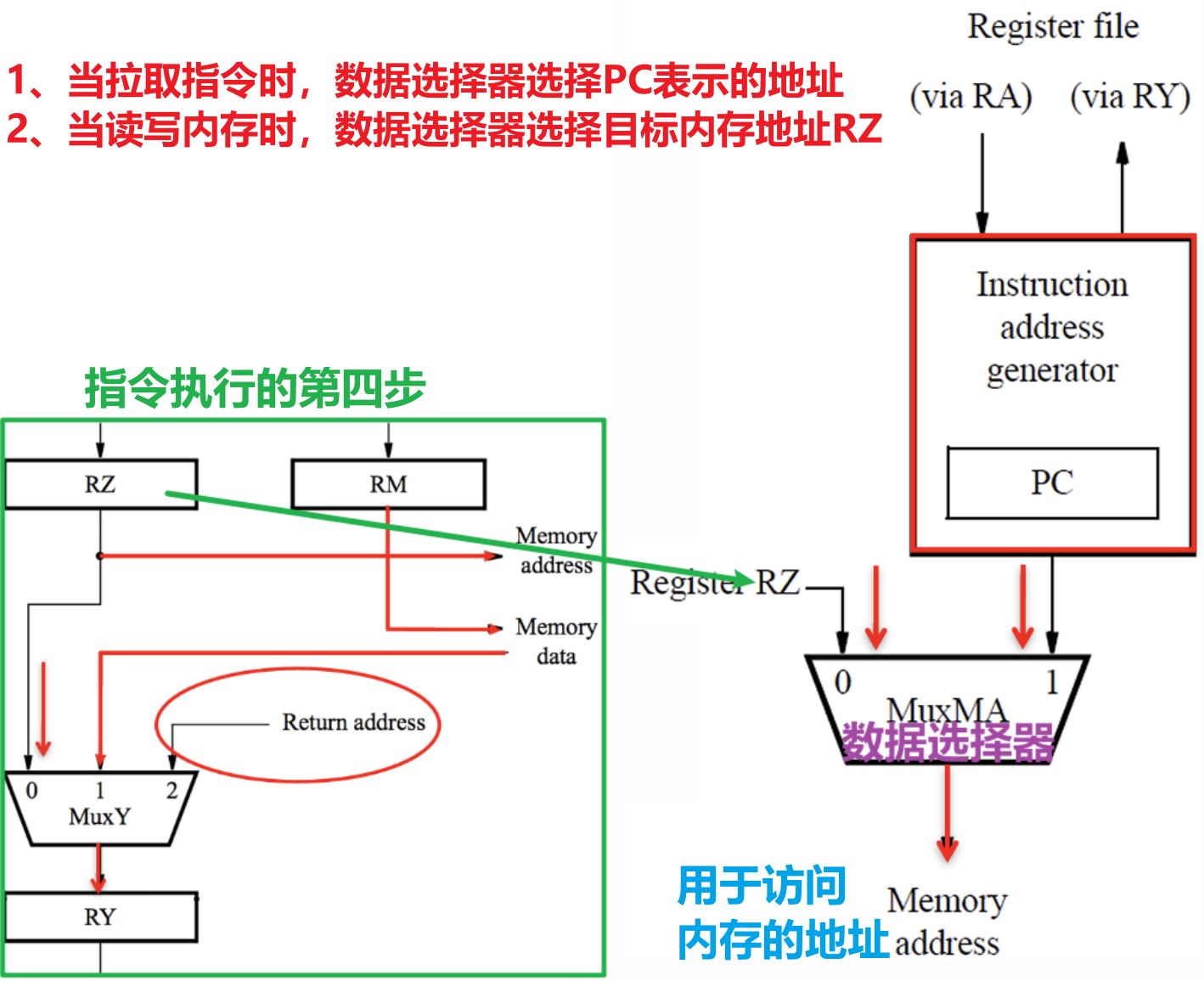
- 指令在加载PC指向的地址处的指令到IR时、指令需要读写内存中的数据时都需要访问内存,而访问内存就需要使用到Processor-Memory Interface这个接口硬件结构
- RZ提供外部内存的地址,我们才得以访问之进行读(Load)或写(Store)的操作
- 如果需要的话,RM提供写入外部内存的数据
- 如果需要的话,从外部内存读取需要的数据到下图的数据选择器的$1$通道处
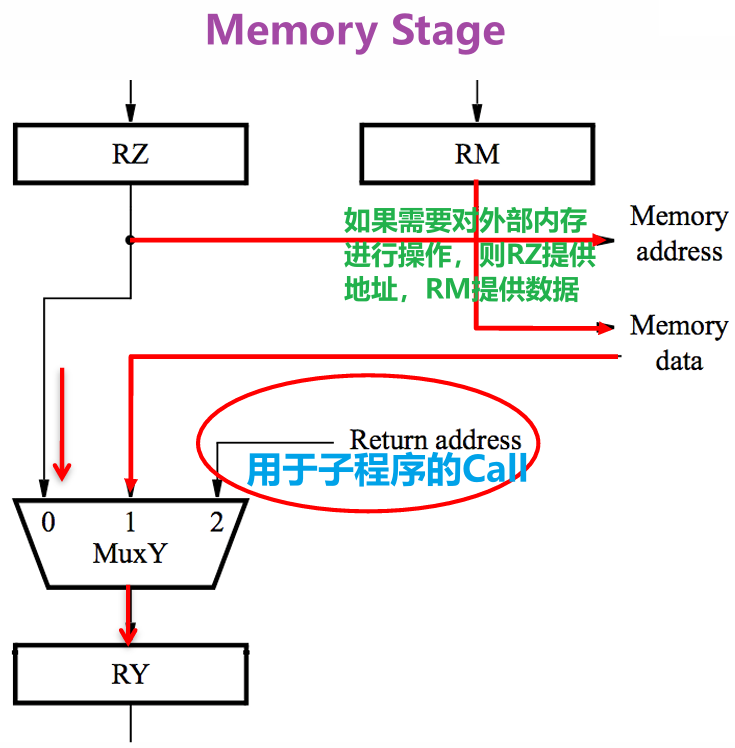
- 指令执行的过程中,该接口处有MAR和MDR在工作
- MAR:主存地址寄存器Memory Address Register(对应上图的Memory Address),MAR用来保存数据被传输到的位置的地址或者数据来源位置的地址
- MDR:主存数据寄存器Memory Data Register(对应上图的Memory Data),用来保存要被写入地址单元或者从地址单元读入的数据
2.4 指令拉取循环
2.4.1 指令地址PC的生成
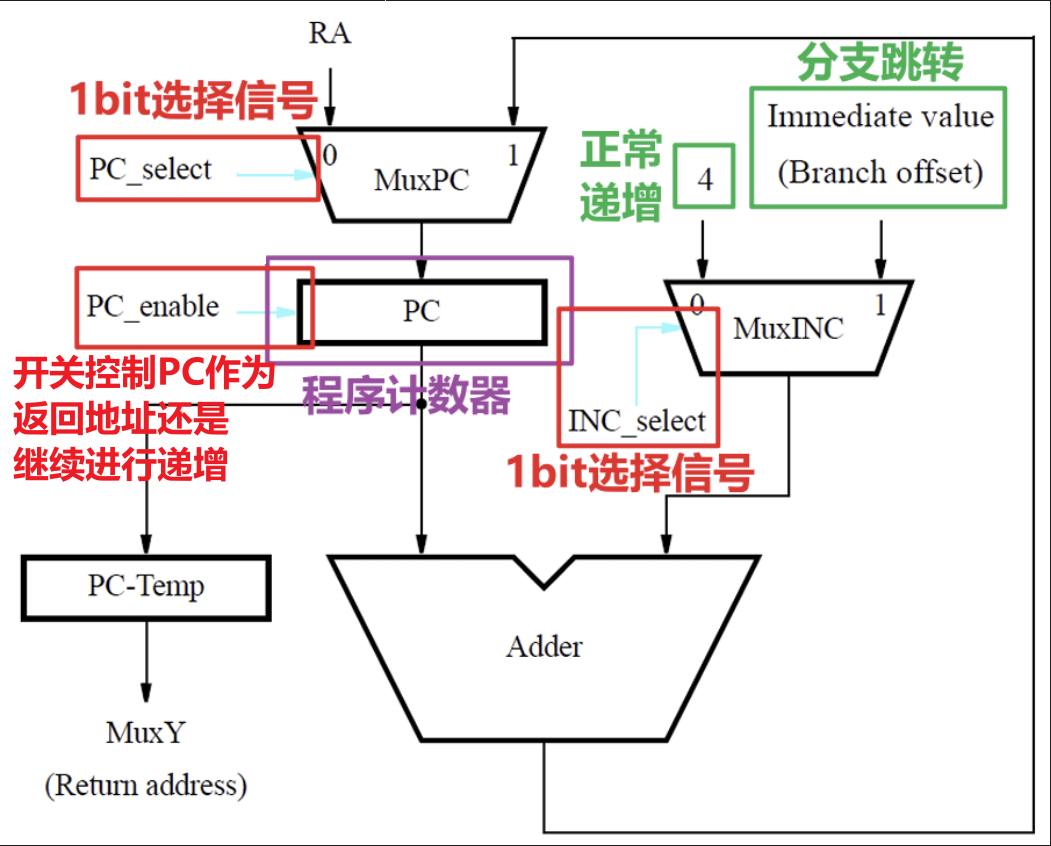
- PC的值代表当前应当执行的指令的地址值,在不跳转的情况下Instruction Address Generator会按照程序中的指令顺序将PC递增指向下一条指令
2.4.2 内存地址的生成
- 拉取指令时,下图的数据选择器会选择拉取PC表示的地址值并正常递增PC
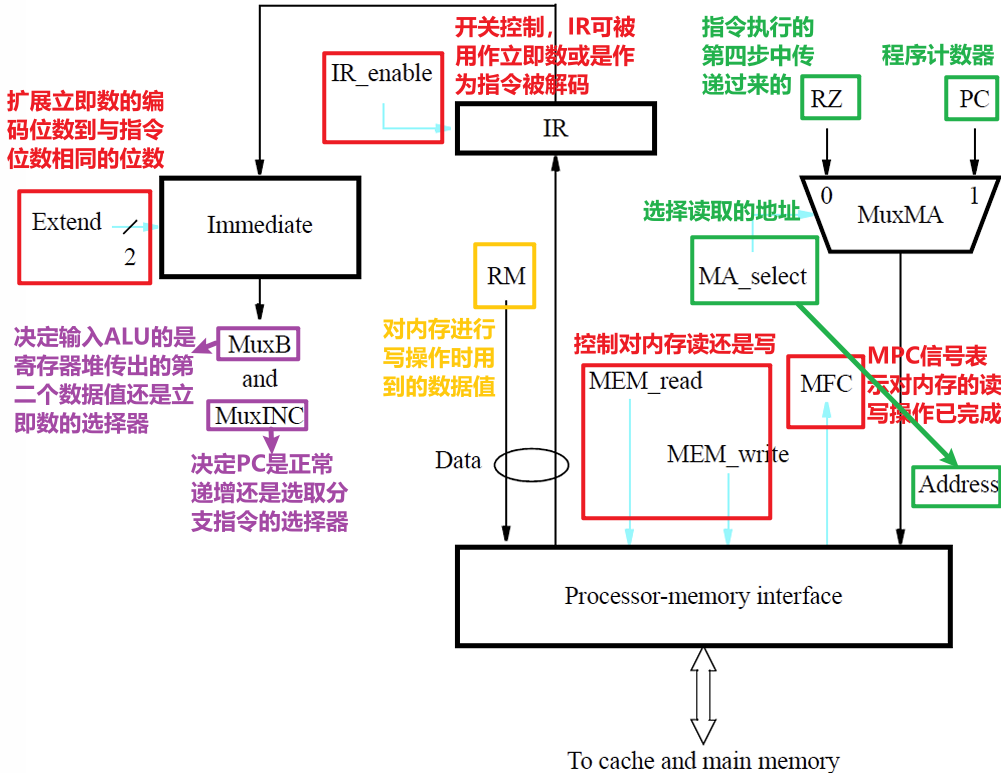
2.4.3 写入IR并翻译指令
- 在拉取循环中,得到当下应当执行的指令在内存中的地址后,将该地址上的指令数据读入IR
- 控制电路继而将该指令解码翻译成控制信号,以驱动指令执行过程中所需的单元部件
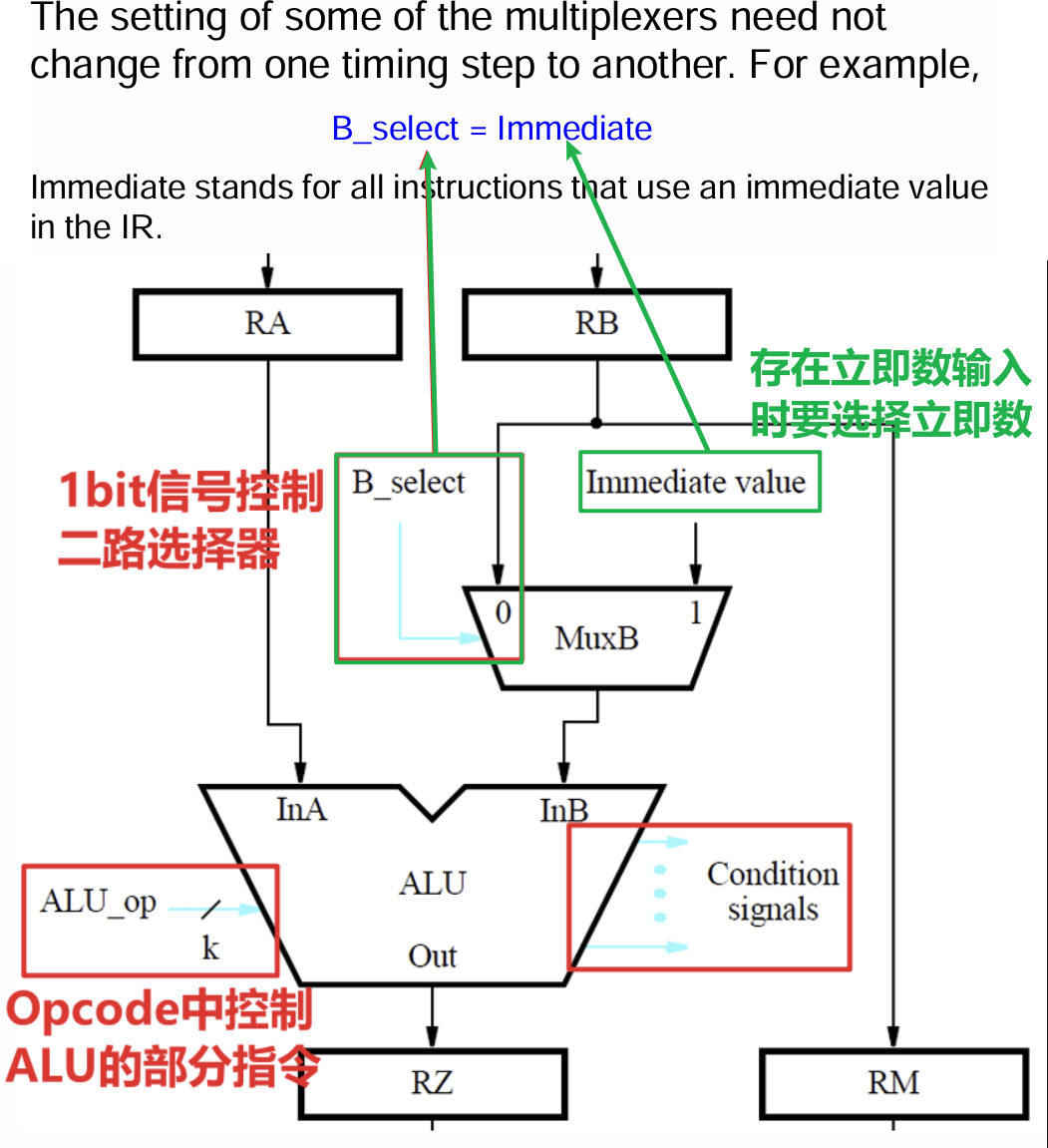
- 若该指令被当作立即数,则其会在需要被用到的时候传入之前提到过的MuxB选择器内
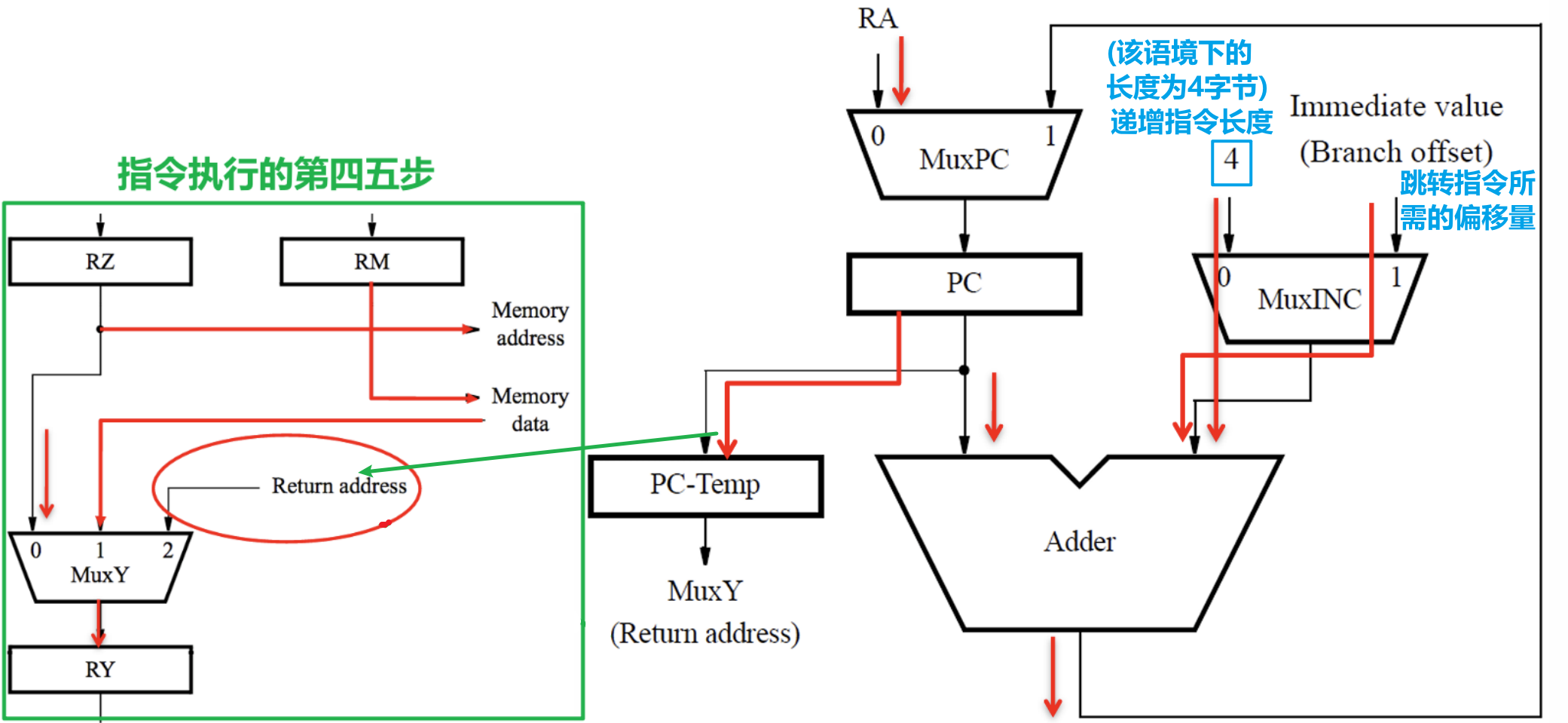
2.5 指令执行案例
- 此处采用的指令为32位(即4字节)的,以下是不同几种指令格式
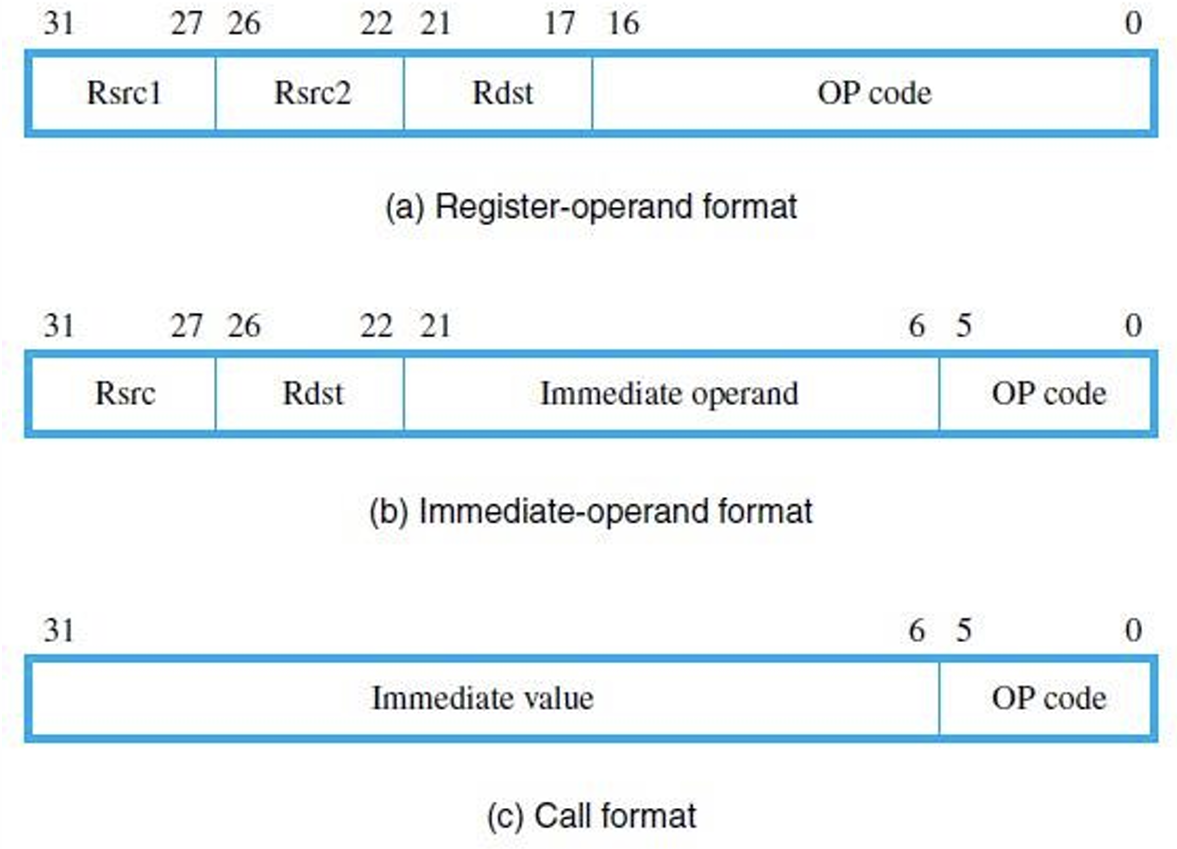
- 三个例子如下
三、子程序及其调用
汇编程序中,有些任务需要(用不同的变量数据)被执行多次,类似高级语言中的函数,这样的一块指令被称为子程序(Subroutine),使用子程序被称为调用(Call),调用子程序的指令需要使用分支操作
3.1 分支操作
3.1.1 非条件分支操作
- 包含非条件分支操作(Unconditional Branch)的子程序调用指令的五个步骤如下图所示

3.1.2 条件分支操作
- 包含条件分支操作(Conditional Branch)的子程序调用指令的五个步骤如下所示,区别于非条件分支操作的那个就是多了一个条件判断的过程

3.2 子程序链接
- 同一个子程序可以在不同的地方被调用,被调用执行完成后必须回到其被调用的地方,子程序链接(Subroutine Linkage)保证其能够返回到正确的位置
- 子程序的Call包含两个操作
- PC递增指向该子程序的下一个指令,将该指令地址保存在Link寄存器处
- Branch到被调用的子程序处执行子程序内容,直至触发Return就Branch到Link寄存器地址处
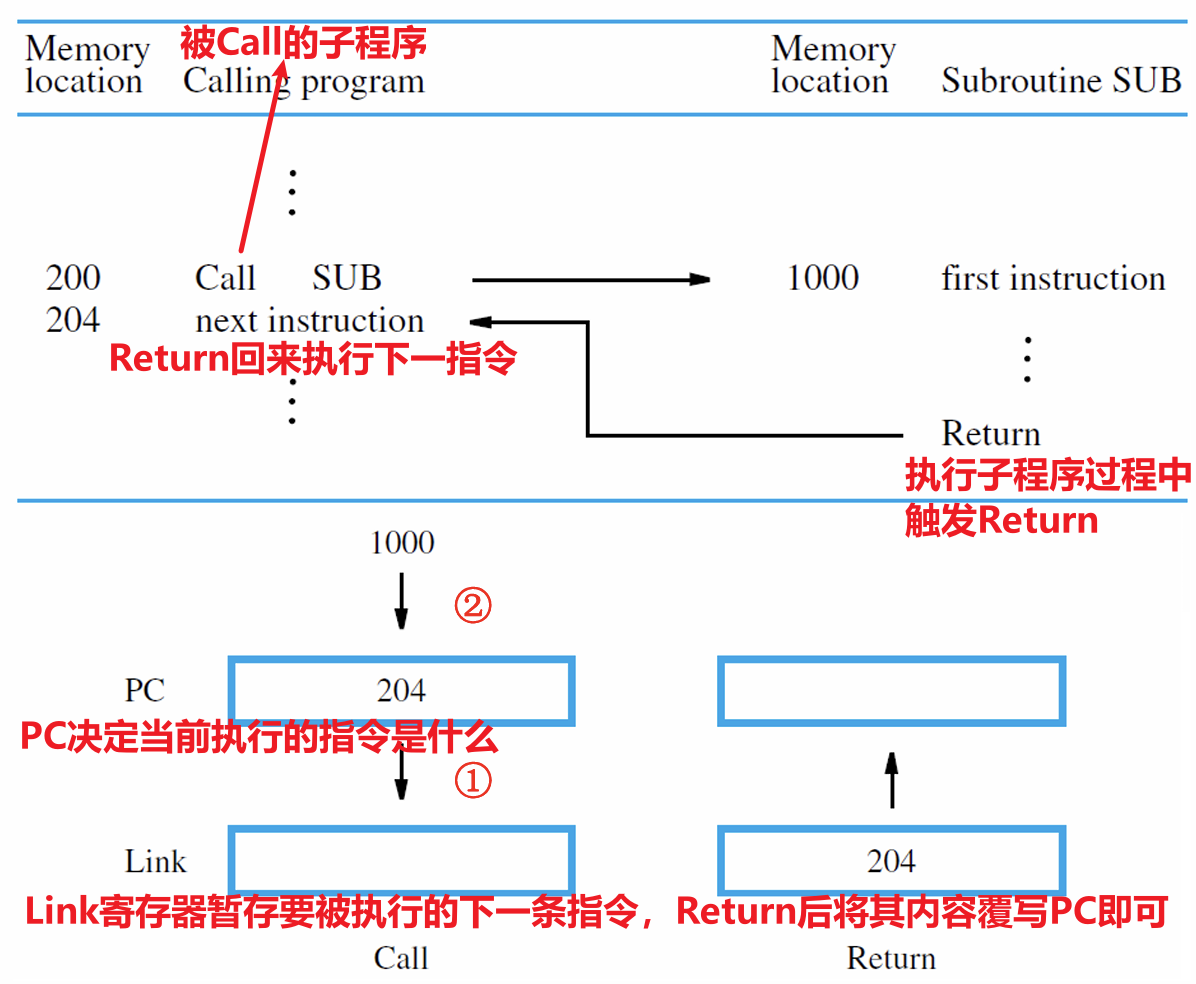
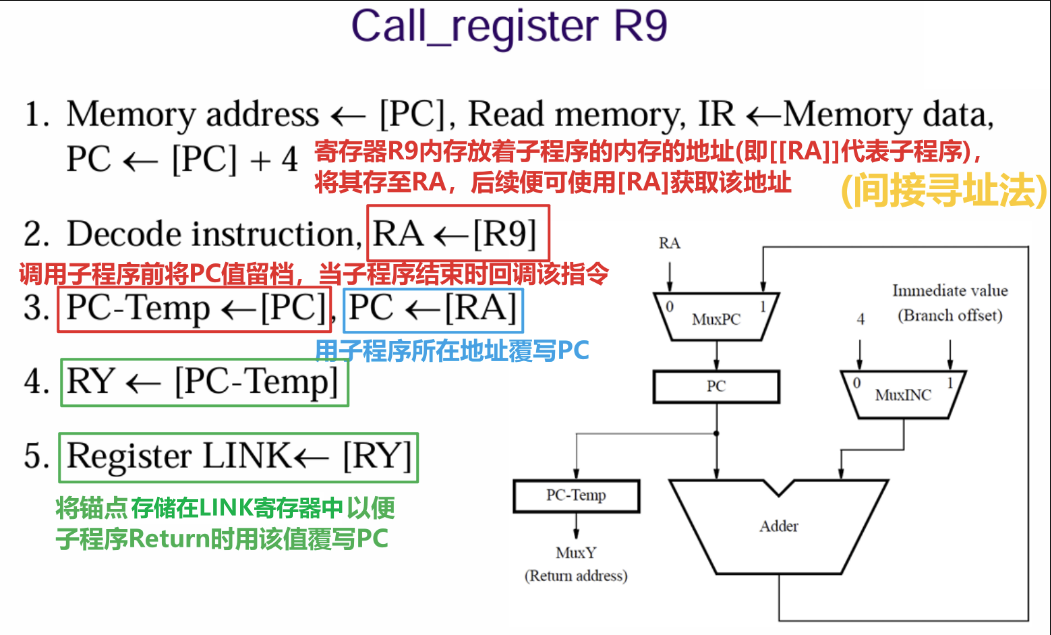
3.3 子程序调用
- 调用子程序的指令的五步骤如下所示,尤其注意第四、五步将Return Address暂存到了LINK寄存器中,这样我们才能在子程序结束时调用Return的时候让PC恢复到调用子程序之前的位置
四、控制信号
指令执行过程中的电路元件需要被(由指令翻译而来的)控制信号触发才能按设想运行,这有时需要额外的中间寄存器来实现,可以参考此处课件对电路原件中的信号的图示
4.1 电路原件的控制信号
4.1.1 多路选择器
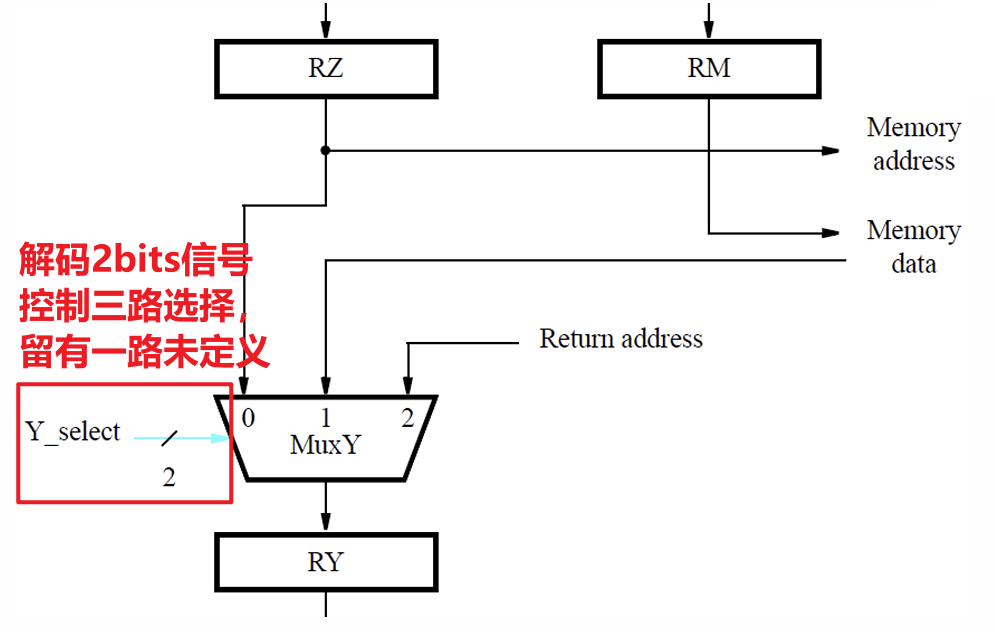
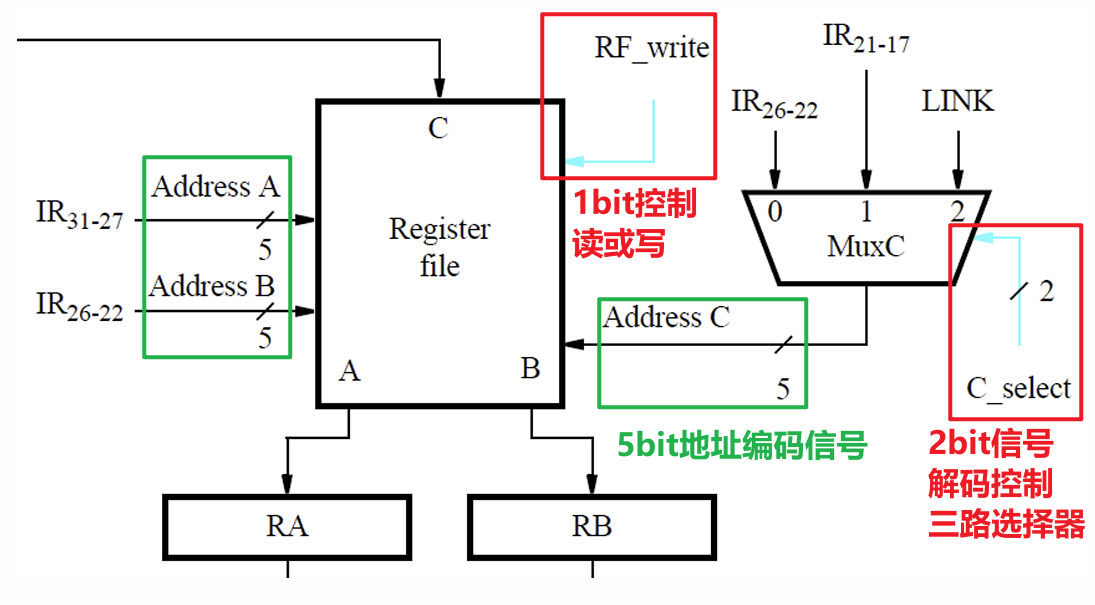
4.1.2 寄存器堆
- 下图中的RF_write信号控制寄存器堆处于读还是写的模式,传入地址时需要的是读模式,而传入ALU计算结果、从内存加载数据进来、调用子程序时记录Return地址时需要的是写模式
4.1.3 算术逻辑单元
4.1.4 指令地址PC生成
4.1.5 内存读写与IR
- 关于MFC是什么,思考以下场景
- 假设我们需要对内存进行访问,当数据在Cache中Hit时,此时访问内存(读写)的操作可以在一个时钟周期内完成
- 否则如果Miss的话,则需要从主存中拉取数据,此时访问内存的操作就需要多个时钟周期,所以内存访问所需的时间长度视不同的情况而可能存在差异
- 所以我们需要一个控制信号MFC(Memory Function Completed)来提示内存的读取操作是否已经完成
- MFC信号被用于指令执行的五步骤中的第一步(若第四步中也需要读取内存,那么第四步也需要等待MFC的产生)
- Step1:已知PC指向一个内存地址,依据该地址读取对应内存并等待MFC信号,确认MFC信号后才可以将地址上的数据写入IR,然后对PC进行递增
4.2 控制信号的产生方式
两种产生控制信号的方式中,硬布线控制是使用硬件的方式,而微程序控制则是使用软件的方式
4.2.1 硬布线控制介绍
- 硬布线控制(Hardwired Control)产生信号的思路总体如下图所示,其中Step Counter产生的五个$T_i$信号都是$1$位的控制信号,$T_i$可用于与其它条件做与运算以计算出某些信号,使其产生必须发生在对应的第$i$步(注意PC是不需要在产生控制信号的过程中被用到的)
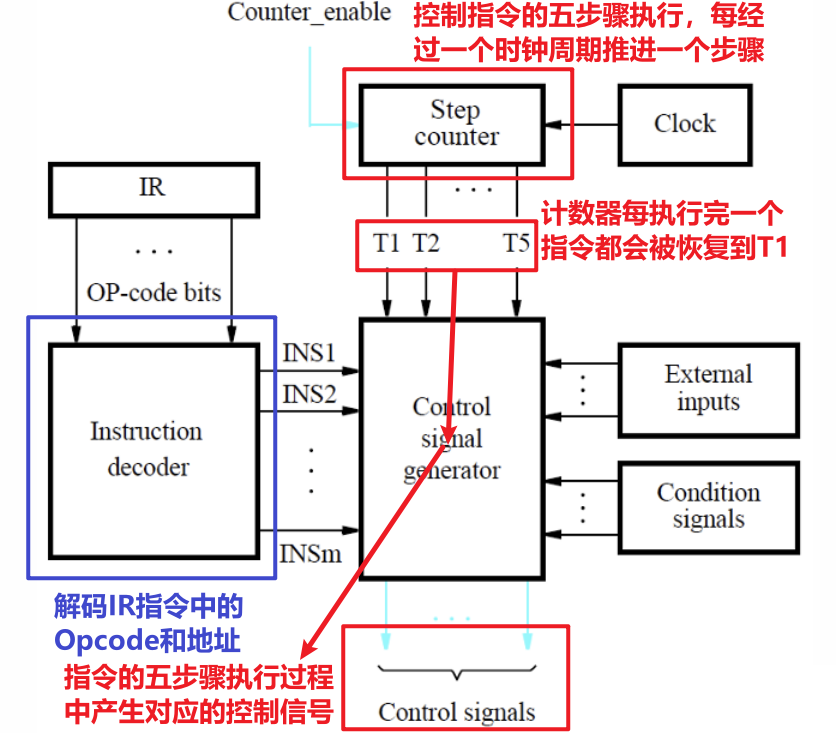
4.2.2 硬布线控制如何产生信号
- 关于Control Signal Generator内部的工作过程,我们以RF_write信号为例,该信号控制寄存器堆的读写模式,当需要传入ALU计算结果、从内存加载数据进来、调用子程序时记录Return地址时需要的是写模式,这些操作都发生在指令执行的第五步骤中,所以该信号应当由上面三种情况做或运算后,再与T5信号做与运算得出(该信号不应当在进行前四步时为$1$,否则此时电路中的数据会直接流入寄存器堆中,从而导致破坏数据)
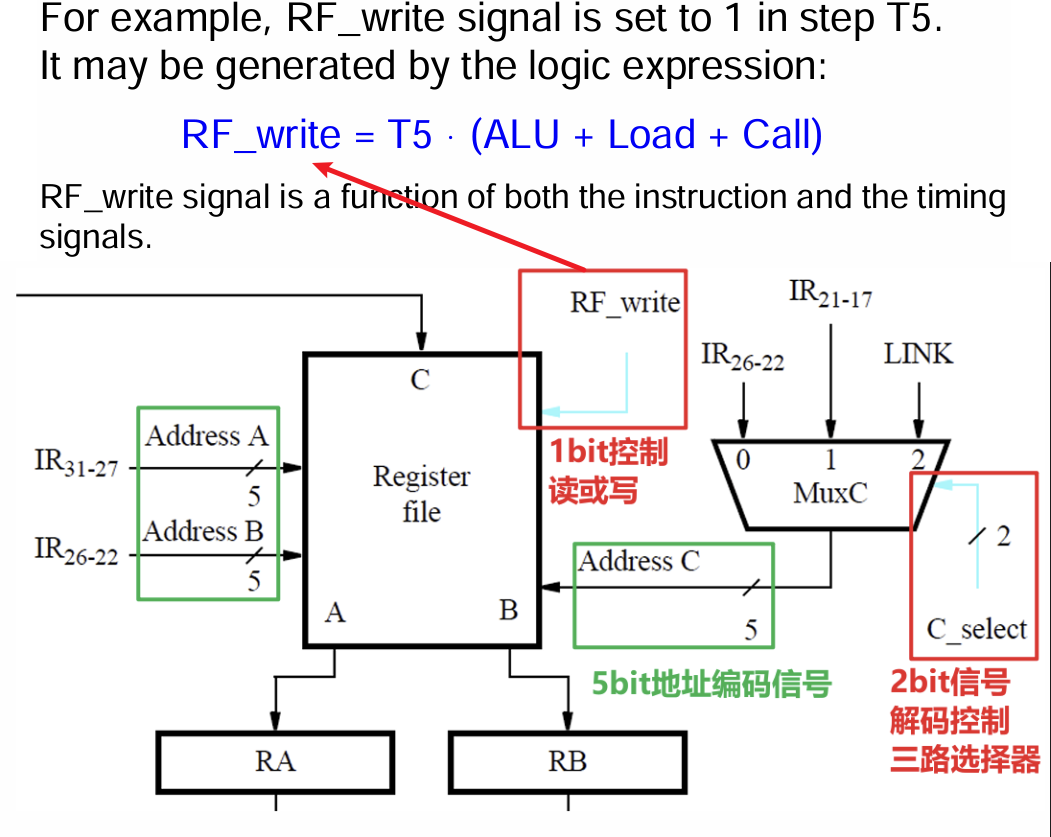
- 我们再以B_select信号为例,该信号控制传入ALU的第二个数值$B$的选择(从寄存器堆中读取,或使用立即数),产生方式是只要有立即数传入,就选择立即数,否则选择另一路
4.2.4 硬布线控制考虑MFC延迟
- 前面我们讲到当指令需要读取内存的时候,会由于Hit和Miss导致的内存访问所需的时间(时钟周期数)不同步的问题,所以需要等待MFC信号后才可以进行指令的下一步骤
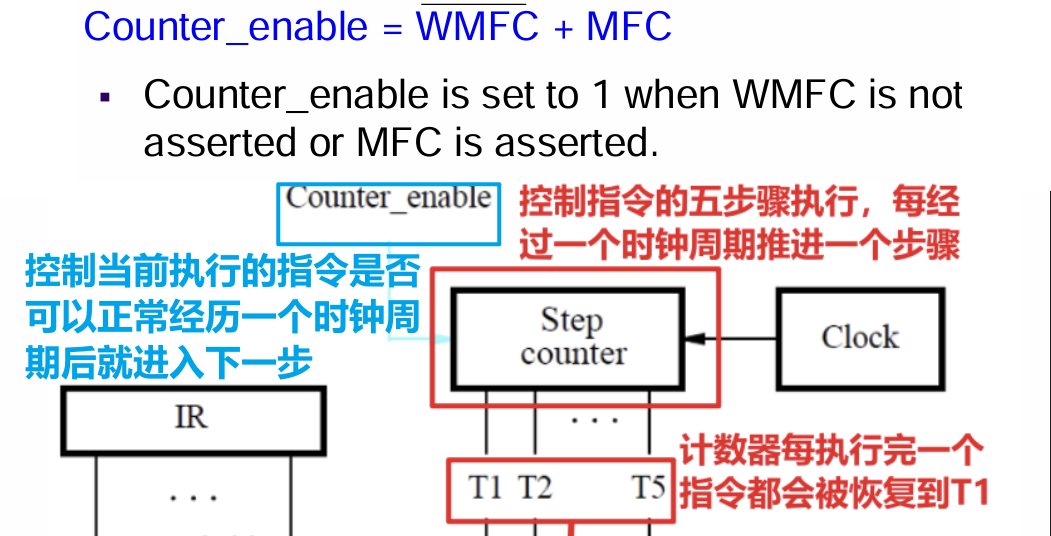
- 控制指令的五步骤按时序执行的信号是Counter_enable,其在默认情况下是$1$,此时Step Counter每经过一个时钟周期就会导致$T_i$推进到下一步骤$T_{i+1}$,所以在等待MFC信号产生的过程中(若Hit就需等待一个时钟周期,Miss则多个)中将Counter_enable设置为$0$以停止步骤推进
- 所以Counter_enable的计算就如下图所示(其中WMFC指的是Waiting for MFC)
- 当没有在等待MFC信号的时候(即执行无需访问内存的指令时)Counter_enable等于$1$
- 或MFC信号产生的时候(即执行需要访问内存的指令时)Counter_enable等于$1$
- 除了Counter_enable,信号PC_enable(控制PC中的值是否能被传输下去)的产生也与MFC有关
- 在指令执行的第一步$T1$时需要先使用此时PC中存储的地址来寻址内存上的对应指令编码值,所以在将PC传输下去(一旦传输,PC的值就会被改变,例如$+4$或$+$分支偏移)之前需要等待访问内存操作完成后返回MFC信号,才可以打开传输开关PC_enable
- 或者在指令执行子程序(即需要进行分支操作)的第三步时,这会需要更改PC的值,如下图
- 所以综合上述两种能使得PC传输下去来发挥作用的情况,PC_enable的计算如下图所示

4.2.5 微程序控制方法中的微指令
- 微程序控制(Microprogramming)产生控制信号的过程中,每个时钟周期内(指令的每个执行步骤一般占用一个时钟周期)的每个控制信号值都被存储在叫做微指令(Microinstruction)或控制字(Control Word)的二进制编码中
- 为什么不是将单条指令整体的所有内容都解码存放在单个微指令内呢?如果这样的话
- 会导致单个微指令过长,遍历其编码序列耗时多,且微指令内未被利用到的操作编码块很多,因为每次执行指令时仅需要激活编码序列中的若干bit位为$1$即可,所以会导致在遍历序列的时候大部分时间是浪费的
- 所以每条指令都会被解码为一组五个微指令(对应指令执行的的五步骤),这组微指令合称为微程序/微例程(Microprogram/Microroutine),其被存放在Control Store中
- 优点:执行指令时可在读取每个微指令时判断该步骤是否需要被操作(某些指令的五步骤中存在占位的空操作),即通过标记位来判断微指令是否需要被执行,以减少无意义的遍历
- 缺点:解码这样一组微指令需要额外的控制电路

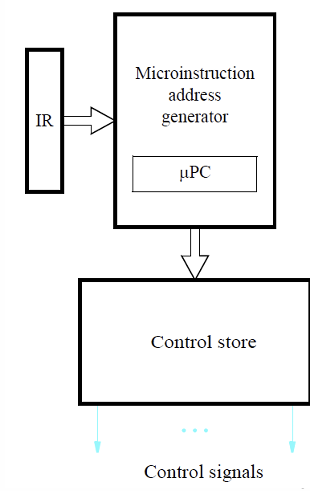
- 所以Control Circuitry解码IR指令的过程实际上就是产生Microprogram的过程,下图中的$\mu PC$就是一个存放当前需要被用于执行的Microprogram所在位置的地址
- 这种方式为CISC指令集体系结构中的复杂指令的实现提供了一定的灵活性,但读取并执行微指令的过程较慢,会导致较大的延迟
4.2.6 对比两种产生方式
- 硬布线控制方式
- 优点:更快(因为是硬件实现)
- 缺点:更贵,操作灵活性低,硬件设计和部署的难度高
- 微程序控制方式
- 优点:更便宜,操作灵活性高,设计部署难度较低
- 缺点:更慢
五、习题训练
5.1 指令的执行

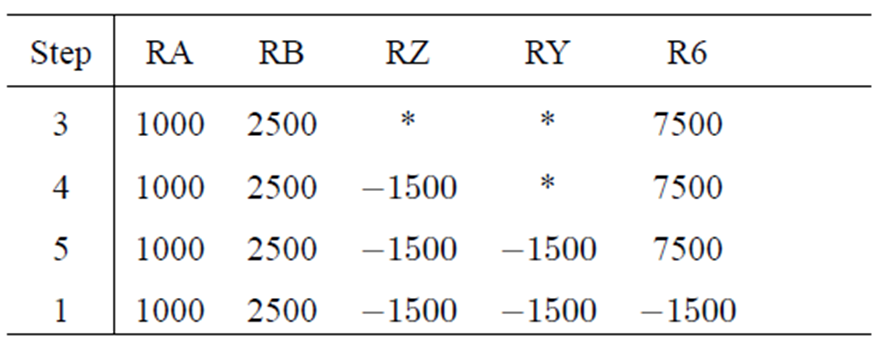
5.2 RISC指令的五步
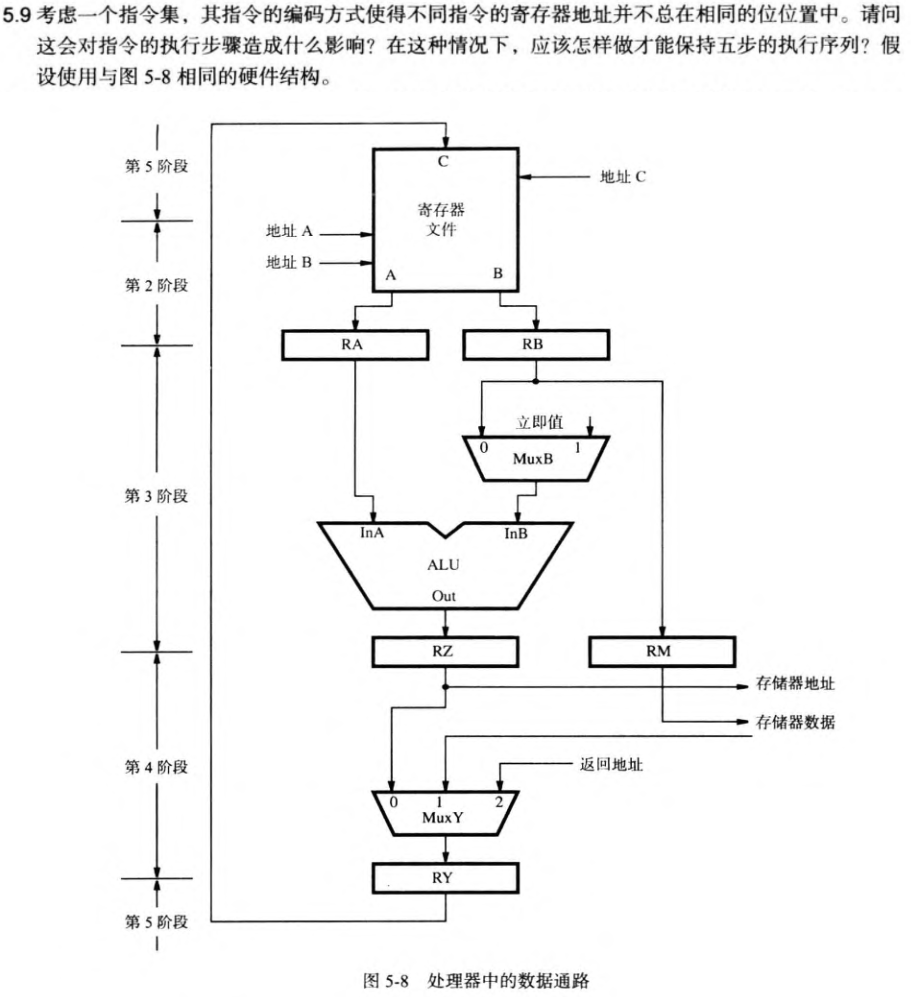

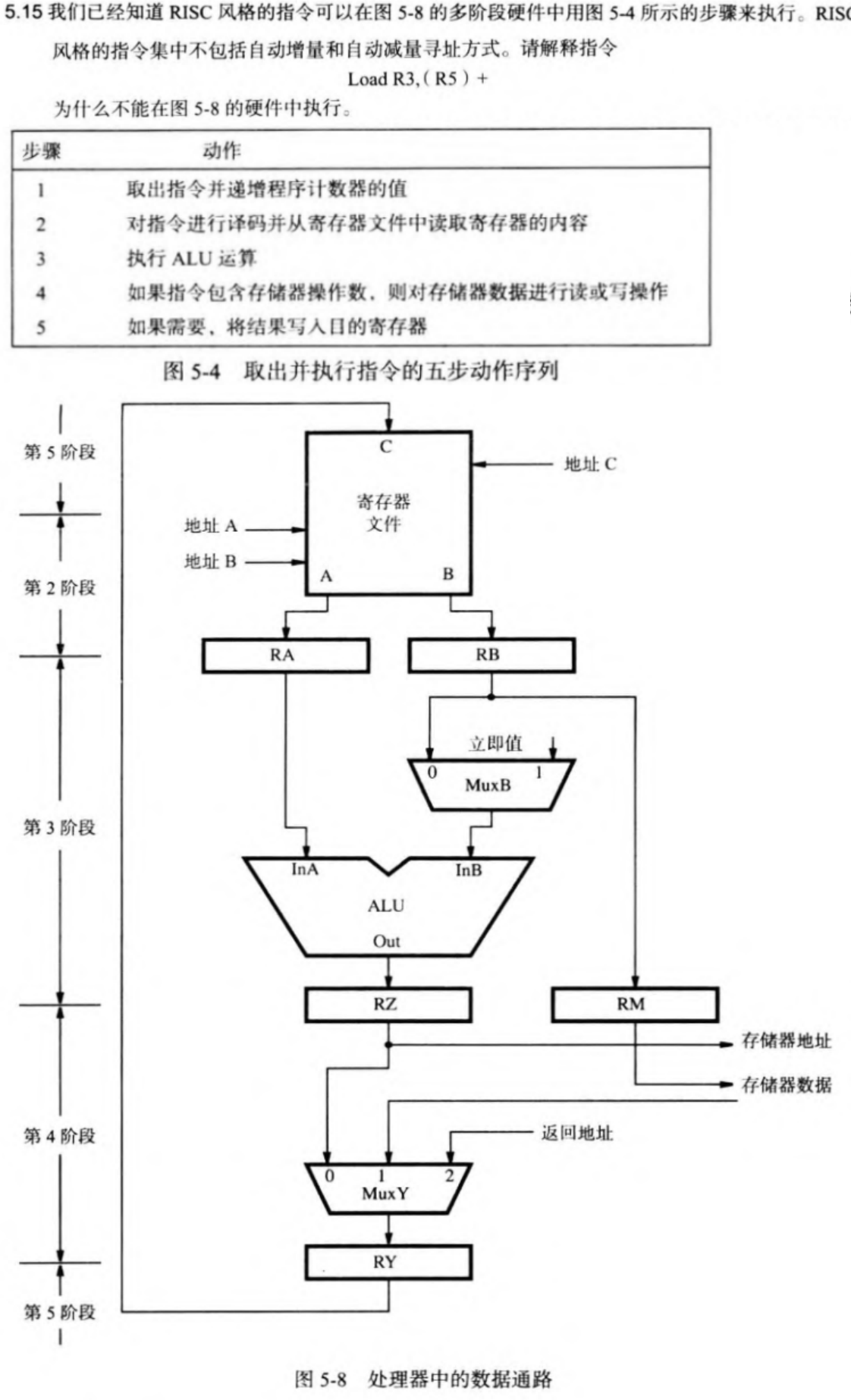
5.3 指令与寻址方式

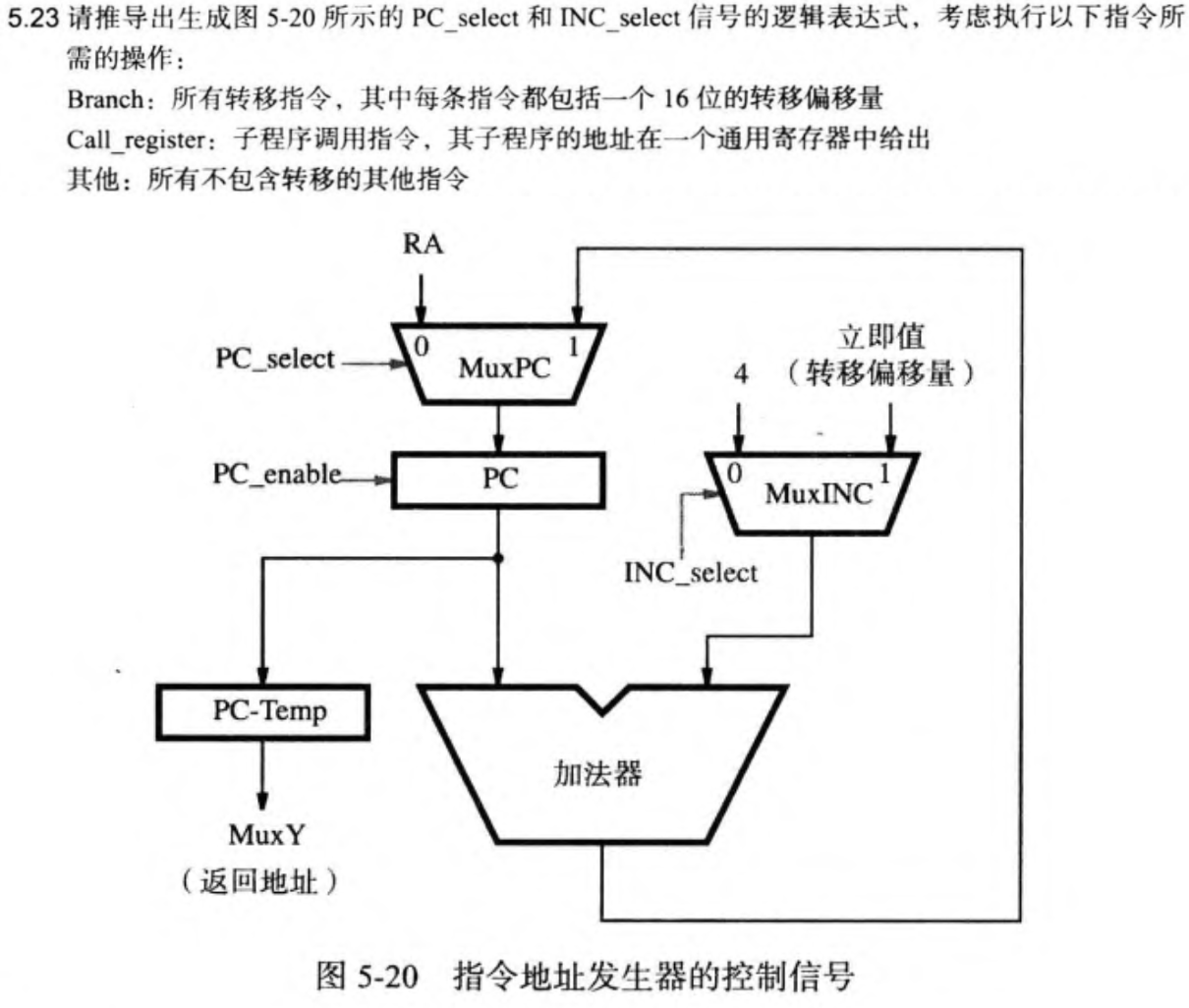
5.4 程序控制信号

本文由作者按照 CC BY-NC-SA 4.0 进行授权